[编程算法] DevOps和MLOps介绍
序言
DevOps是Development和Operation的组合词,也即开发&运营,顾名思义DevOps是一门如何促进软件开发过程中协同和产出效率的运营哲学,其涵盖内容包括开发高质量软件所需的文化哲学,操作范例,工具等。MLOps`则是DevOps在机器学习领域的延伸,是将Machine learning与Operation完美结合的理论方法。要达到这个目的,我们需要了解一些项目管理,软件架构和持续集成/持续部署(CI/CD)的知识与概念。
正文
1. DevOps的概念介绍
DevOps概念的产生源于现代软件的需求与复杂程度的提升。由于软件开发越来越复杂, 开发人员的技术水平,背景知识,以及编程习惯都会有一些区别,因此从企业的角度来看,如何高效统一地使用某种方法或工具来更好地使所有参与人员协作就变得尤为关键,而DevOps就是对企业来说优化软件开发和维护成本的最佳解决方案。
DevOps与传统开发模式的最大区别就是其不像传统开发模式那样不同团队完全独立分工运行(例如IT系统和软件开发团队分开),它会增加不同团队间的协作和交流。除此之外,DevOps与传统模式不同的是其发布和反馈模式,传统模式由软件开发团队负责从计划到最终产品发布的开发周期中的所有步骤,因此知道完整的产品被投放在市场中后才能知晓市场对产品的反应;而DevOps则会使用Minimum Viable Product(MVP),即基础功能产品来首先测试市场反馈,如果市场反馈较好,再增加功能和投资,开始新的开发周期,而如果某次更新的市场反馈较差,开发团队也可以更容易分析原因,用较小的成本对产品回调或改进。且由于DevOps会在开发过程中考虑用户反馈,而且MVP的开发时间会明显短于最终产品,这会使DevOps开发的产品于质于量都优于传统开发模式。
1.1 DataOps 和 MLOps
就像我们文初提到的,DevOps除了在常规的软件开发项目中协调基础IT设施与产品开发的操作以外,它的概念还能应用于数据工程或机器学习等项目中,不过由于开发产品性质和维护周期都不一样,他们使用的方法流程甚至工具也都不尽相同,也因此在数据工程中的DevOps被称为DataOps,而机器学习项目的DevOps则被称为MLOps。
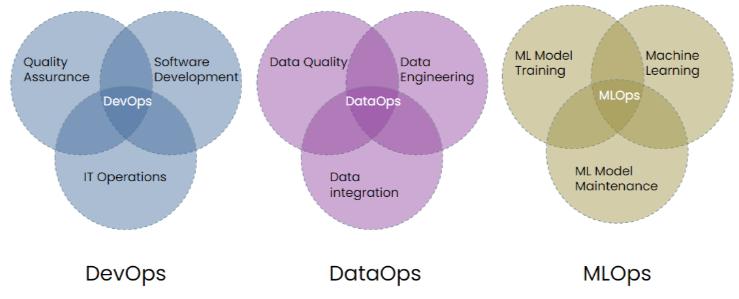
DataOps主要应用在数据工程领域,用于优化数据管道的创建和维护,主要流程是ETL(Etract, Transform, Load);MLOps则是注重机器学习模型的训练,测试,部署和维护。
1.2项目管理方法
项目管理的定义就是使用特定知识、技巧、工具、和技术来像人们提供有价值的结果。任何团队无论其最终目标是何,都需要一套提前规定的规则和框架来规范。项目管理对DevOps来说非常重要的原因是其定义了不同团队协同按时完成某个共同目标的方法方式。这里介绍两个常见不同的项目管理方式:
瀑布开发(Waterfall):使用线性的流程从计划到开发到生产,一旦某个阶段的成果达成就进入下一个阶段而不再回头,最后阶段的产物将是集成所有功能的最终产品。
敏捷开发(Agile):该方式由一系列的开发周期组成,每个周期都有一个较小的目标成果,例如完成一个MVP,添加某些功能,或更改某些设计等,团队间针对不同的周期灵活互动,最后每个周期的结果如果未得到市场认可,则可以回到早期阶段重新调试。
不同的项目管理方法可能适用于不同的情况,但近年来Agile方式开始被越来越多的软件管理团队使用。而Agile本身也有很多种不同的操作方式,这里介绍两种最重要的:Scrum和Kanban。Scrum和Kanban的主要区别在于Scrum有一个2-4周的开发目标的冲刺阶段(Sprint),在每个冲刺结束时检查开发成果;而Kanban则是使用可视化工具等方法持续跟踪开发进度。另外的区别还有Scrum中不同的人员有不同的分工例如Scrum master和Product owner等,而Kanban则使用分布式的责任划分。需要注意的是这两种操作方式都是敏捷开发的一种,将其应用在适用的场景下非常重要。
1.3 DevOps的变革管理模型
DevOps的变革管理模型(Change management model)包括多个阶段:需求,设计,开发,测试,部署,检讨,上市。
需求(requirements)通常是组织的领导决定,为了实现商业期望和成果,产品专家决定产品需求。- 需求决定后进入
设计(Design)阶段,产品工程师开始设计产品的软件架构,也就是决定产品的各个构成要件之间如何互动,基础设施工程师也要开始设计他们如何从系统层面支持新产品,数据工程师需要决定新产品的数据需求,例如需要何种数据,并且设计数据管道等。 - 设计结束后,产品进入
开发(Develop)和测试(Test)阶段,DevOps模型中,产品工程师和基础设施工程师将会一同工作以快速达成最好结果:产品工程师以客户交互体验为目标开发,而基础设施工程师则对产品运行的系统负责,开发完成后数据工程师提供一些测试数据来模仿真实用户,以测试产品功能。最佳实践是测试与开发同步进行,在进入下一阶段之前,产品应该就多种可能遇到的情况进行周全的测试以确保用户体验。 - 开发完成后,新产品可以被
部署(Deploy)至小部分用户以获得反馈,该过程称为实验(experiment),产品或软件若在这个阶段被用户反馈较差,则可以重新回到设计阶段重复开发周期。
循环开发(Cyclical development)是DevOps的一个重要原则,其中心思想就是通过不断吸取反馈而不断优化产品,一个产品发布后其表现会被持续监控优化。
1.3.1 基础设施(Infrastructure engineering)
接下来我们看看软件开发的基础设施有些什么:
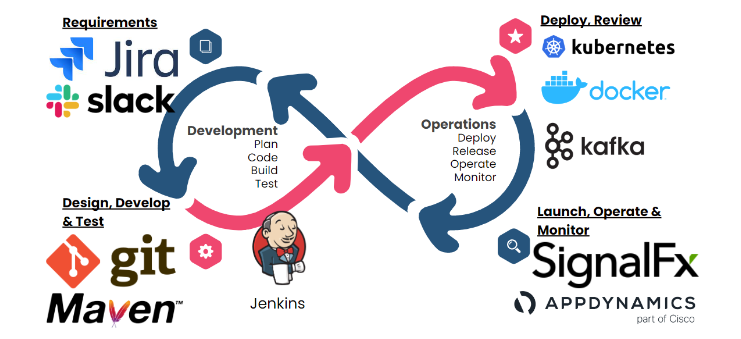
开发者平台(Developer Platform):开发者平台为开发者提供开发所学的工具和系统,保证代码开发的体验。代码库和版本控制(Codebase & version control):开发者在其电脑上开发完代码后需要将其代码与公司正在使用的其他代码合并,代码库也就是存放代码的仓库(repository),如Github repository。而版本控制则是使用Git等工具来确保每次代码的提交都能被记录处理,从而确保代码安全更新。Git中有一条主分支(main branch)是生产中使用的代码,开发者不直接在主分支上修改代码,而是创建其自己的版本分支,每次开发者完成其开发部分之后,由其他开发者检查代码并测试通过之后这些变革再被合并至主分支。持续集成/持续交付管道(CI/CD pipeline):其实上条提到的版本控制也是CI/CD的重要组成部分,CI/CD的主要功能是自动化管理并集成代码变化至软件的代码主体,确保各个开发者提交的代码在合并至代码主题前被完整测试过。部署平台(Deployment platform):部署就是将软件投入使用,此时软件开会时与用户互动,并提供功能服务。
1.4 DevOps分析与报告
对DevOps的分析报告让我们对软件和数据的进度状态掌控了解,DevOps的每个阶段都会产生不同种类的各种数据供我们分析。在需求阶段,我们的工作主要从商业角度出发,因此这个阶段可以追踪创新节奏和开发的产品功能数量等;在设计开发和测试阶段,分析报告的主要侧重点是追踪“计划”,“开发”,“组建”, “测试”等每个阶段的耗时,产出质量等。产出质量可以用代码通过的测试数量,CI/CD管道的稳定性等界定;在部署和反馈阶段,开发者可以通过对实验做A/B testing来确定新版本的软件是否比旧版本更受用户欢迎;在产品实际上市后,它还需被维护并监控,以确保产品一直如预期运行,监控过程中会产生许多log文件,而这些logs也都可以作为报告数据来源。
1.5 DevOps相关工具
DevOps开发周期的各个阶段都有各种专门的工具辅助开发流程,这里介绍其中一些比较有名的工具:
需求阶段:这个阶段需要开发人员与业务人员交流较多,因此这个阶段使用较多的工具也都是以加强交流为主,例如便于产品管理的JIRA,便于交流的Slack或Discord。
设计,开发,测试阶段:软件变革管理阶段可以使用的工具选项非常之多,但其中最为重要的一个就是作为版本控制软件的Git,而与之配合使用的平台有GitLab或者Github。源代码完成后需要进入组建阶段(build)用以生成可执行文件,最常见的组建系统有Maven和Gradle。CI/CD pipeline是DevOps的根本之一,也就是自动化组建, 测试与部署,CI/CD pipeline的主要工具有Jenkins和Circle CI。
部署阶段:微服务(Microservices)架构中,每个微服务都被独立开发部署,其使用容器化方法来保持其独立性,每一个容器都是一个软件运行的环境,因此一个服务器中可能同时运行成百上千个容器,使用容器的主要软件有Docker和Podman,而Kubernetes则是管理多个Docker容器的工具。
监控工具:产品部署并发布到市场上后需要被严密监控,这样我们才知道软件的表现如何,是否有任何质量问题等。主要的软件监控工具有SignalFx和App Dynamics。
数据管理工具:Apache Kafka是最广泛使用的微服务架构数据管理软件,微服务在Kafka上发布其log文件,其他服务在Kafka上监听,因此微服务通过Kafka交流信息。
数据管道管理工具:数据管道管理工具可以用来管理Batch process或者streaming数据,主要工具有Apache Airflow, Hevo Data, Prefect。
1.6 DevOps文化
协作(Collaboration):协作是DevOps的核心思想,DevOps就是为了开发和运营团队的协作而存在的。自主化团队(Autonomous teams):自主化团队的意思就是团队内部具备开发所需的所有技能,也就是说团队自己就可以运行。责任分担(Shared responsibilities):自主化团队通常对软件的某个部分负责,例如他们可能负责开发和维护某个微服务,因此团队是自主的,因此他们可能要负责从开发到运营维护的所有责任,也即"you build it, you run it"。自动化(Automation):自动化是DevOps的关键,尤其是CI/CD pipeline让我们可以把变革管理,测试和部署自动化,为团队省下大量时间做更有意义的工作。事后反思(Post-mortem):错误不可避免,再好的软件也会出现错误,关键在于当出现并解决问题之后,如何将问题记录并分析从而避免下次出现类似问题,团队应该有事后反思会议用来复盘出现的问题,需要注意的是事后反思不是找人背锅,而是从团队的角度系统化地控制问题。
2. MLOps
如前文提到的MLOps就是DevOps的精神在机器学习领域的应用,也即机器学习运营。我们需要MLOps来保证数据质量、特征工程、模型表现、模型部署、和持续监控等机器学习的应用过程中各个步骤之间准确无缝高效的衔接。通常来说MLOps的过程可以分为三个阶段:设计(Design)、开发(Development)、部署(Deployment)。
2.1 设计阶段
在设计阶段,我们通常首先要明确要解决的问题(Context of the problem)并且评估使用机器学习的附加价值(Added value),收集如何定义成功的业务需求(Business requirement)和用于追踪进度的关键指标(Key Metrics),最后保证高质量的**数据处理(Data processing)**也是获得稳定模型的关键。在这个阶段,我们需要与关键的业务部门对接来评估项目可行性并且做出有效决定。
- 价值附加:通常对机器学习项目来说,其附加价值可以用时间或金钱来衡量,要么是因为机器学习节省的时间,要么是因为项目结果多获得/少付出的钱。
- 业务需求:除了附加价值外,我们还要考虑业务的需求,尤其需要考虑终端用户需要如何使用我们的机器学习模型。比如我们要考虑预测的频率和速度,准确性以及可解释性。除了用户外还需要考虑法律法规,预算和团队大小等因素。
- 关键指标:针对不同的环境和对象我们可以设计不同的指标。例如对于数据科学家来说,我们的指标是算法模型是否足够准确;对于业务人员来说他们的指标则是我们的模型对解决他们的业务问题提供了多少帮助,例如增加多少客户满意度,增加多少收入。
- 数据处理:数据收集也是设计阶段的一部分,在这个部分中我们需要调查数据质量并且提取所需的数据。根据数据管理框架DAMA-DMBOK的指引,数据质量既包括高质量数据本身,也包括衡量和改进数据质量的过程。数据质量是所有机器学习的根基,其中有4个维度评判数据的质量:准确性(数据是否可以信赖),完备性(数据是否足以反映手中问题),一致性(数据定义是否一致),和时效性(数据需要多长时间备好)。
| 维度 | 问题示例 | 维度质量示例 |
|---|---|---|
| 准确性(Accuracy) | 我们的数据是否正确描述顾客? | 数据中客户年龄为18但实际是32 |
| 完备性(Completeness) | 客户数据是否有缺失? | 80%的客户没有姓氏资料 |
| 一致性(Consistency) | 客户的资料状态是否全公司同步? | 客户状态在一个数据库中为激活,另一个显示未激活 |
| 时效性(Timeliness) | 客户的下单指示数据何时可用? | 客户下单数据只能在每天晚上同步而非实时 |
2.2 开发阶段
在开发阶段,我们需要创建我们的机器学习模型(ML model),用各种不同的数据、算法、或者参数来做实验(Experiment)并找到最适合我们问题的解决方法,实验中我们需要不断训练多个模型并评估它们的表现并根据实验结果调整设计。我们的最终目的是要找到一个不仅可以满足关键指标而且可以部署用以解决现实问题的模型(Model ready for deployment)。
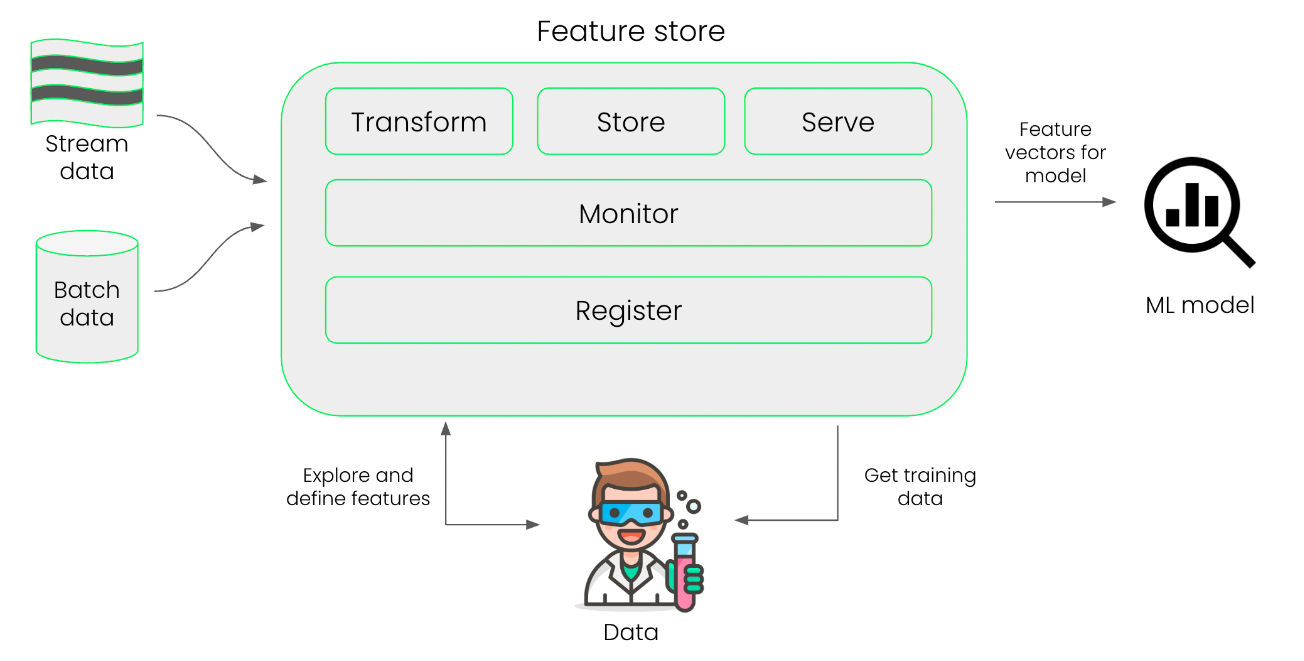
特征工程(Feature engineering):特征工程就是把原始数据处理成具有一定预测能力的变量的过程。例如我们原始数据中有客户的消费金额和单量,这时我们可以计算出客户的平均单价(消费金额/单量),用来衡量客户的消费能力,这时我们就创建了一个特征。当机器学习项目数量增加时,特征工程的成本可能会增加,因此将一些常用的特征储层在一个专用的特征库(Feature store)中可以较大增加机器学习的效率。
实验追踪(Experiment tracking):在机器学习中,我们通过实验来训练并评估多个模型的表现从而选取最好的模型,而在每个实验中我们也需要测试不同的参数配置来选取最好的配置。在每次实验中我们都需要配置不同的模型,不同的参数,不同的数据版本,不同的代码甚至不同的环境,因此这些配置文件会非常巨大以至于我们需要保存每个做过的实验配置参数,这也就是所谓的实验追踪。
2.3 部署阶段
在部署阶段,我们需要将我们的模型部署到业务生产中,确保它和其他系统无缝连接并交互,我们甚至可以把模型布置成微服务来方便使用。此外我们还需要设置**监测系统(Monitoring system)**来监测模型表现,发现数据偏移,在模型预测表现降低时及时警报。持续监测才可以保证我们的模型一直有效运行且能持续带来价值。
运行环境(runtime environment):由于我们训练模型时的模型运行环境和实际生产中的运行环境会有区别,因此我们可以使用容器(Container)来承载运行环境,将机器学习模型部署成容器是目前主流的MLOps方式。
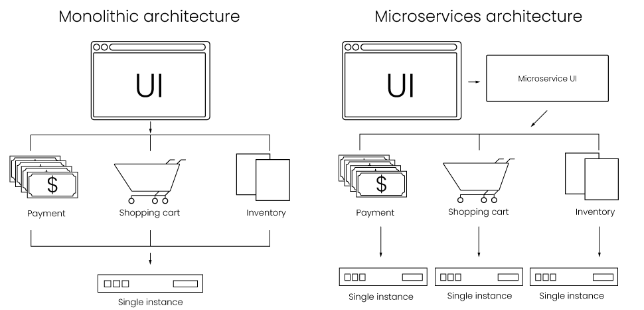
模型部署架构(deployment architecture):单一架构(Monolithic architecture)对比微服务架构(Microservices architecture)的开发成本低,但维护成本更高,因此单一架构适合一些较为简单的小项目,而相对的微服务架构则适合一些复杂且预算充足的项目。我们可以将机器学习模型部署为微服务,并让其他服务通过API调用模型输入输出来使用模型。
CI/CD pipeline:如第一单元所讲,所谓CI/CD就是持续集成和持续开发。其中持续集成(continuous integration)的思想是指代码改动可以持续快速高效地被集成至主体,每个改动都可以在提交并入主代码前被自动测试,以此来确保不同的开发者可以在同一代码上共同协作;持续交付(continuous deployment)则是自动发布CI阶段验证过的代码至生产环境。简单来讲CI是编写代码时的操作,CD则是代码编写完成后的操作。
部署策略(deployment strategy):部署策略是指模型换新的方式,常见的部署策略有三个:基本部署策略(basic deployment strategy)是简单地直接将生产环境中的旧模型换成新模型,所有的新数据都直接发送给新的模型;影子部署策略(shadow deployment strategy)是将新数据同时发送给新模型和旧模型,生产中依然使用旧模型但同时对比两个模型的结果来测试新模型的表现;金丝雀部署策略(canary deployment strategy)是在生产环境中使用新模型,但只在小部分新数据上使用,这样如果新模型有问题也只会影响这小部分用户。不同的部署策略就是在新模型风险和计算资源中权衡利弊。
模型监测(monitoring):统计监测(Statistical monitoring)主要关注包括预测在内的输入和输出的数据;计算监测(computational monitoring)主要关注运行相关的技术指标;模型部署运行一段时间后我们可以获知此前预测案件的实际结果,这些结果我们称之为基本真相(ground truth)。通过对比模型预测结果与基本真相,我们可以测量模型的表现变化,这个过程我们成为反馈回路(feedback loop),通过反馈回路我们可以分析模型错误的时间和原因,包括是否在某些特定类群上出现错误等。
模型重训练:现实世界在时刻变化,历史数据并不总是能反映未来,因此我们训练好某个预测模型后还是要常常重新训练模型以适应现实世界中新出现的规律。通常来讲世界规律的变化在数据的世界中会体现在两个方面,一个是数据漂移(data drift),一个是概念漂移(concept drift)。前者是指输入数据结构的变化,例如过去我们的数据以年轻人为主,而现在的盘面中有了更多的老年人,数据漂移有可能导致模型表现下降,但也不是必然;而后者的概念漂移则是指输入数据与目标标签的关系发生改变,例如我们的客户购买习惯可能发生了变化,导致以前同样的情况下客户会购买某个商品,但现在却不再会购买,这种情况下模型的表现会受到严重影响。模型重训练的频率取决于业务性质(是否市场环境易变),训练成本,对模型表现的需求等。
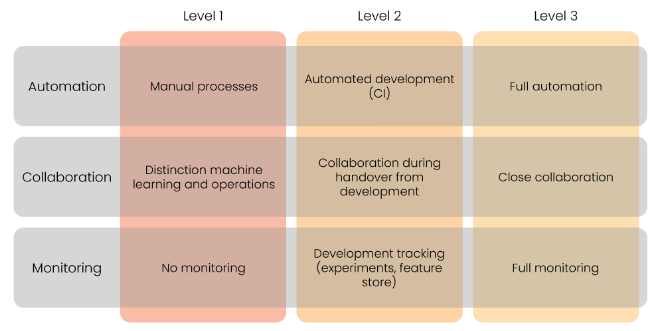
2.4 MLOps成熟度
根据自动化,协作,以及监测的程度,我们可以定义MLOps的成熟度,需要了解的是MLOps的成熟度并不是越高越好,因为更高的成熟度意味着更高的复杂度和成本。第一阶段的MLOps开发和部署都是手动完成,ML和operation分开完成,没有团队协作,开发没有版本和变更记录,部署后无监测;第二阶段有自动化的开发管道,模型部署依然手动完成,模型开发完成后团队协作部署模型,会记录ML实验和特征,模型部署后有较低程度的监测;第三阶段开发和部署都可自动化完成,团队间紧密协作,开发和部署过程完整监测,自动化触发模型重训练等。
[第42篇]





