[编程算法]论文解读《Attention is all you need》
前言
随着最近ChatGPT的爆火,自然语言处理(Natural Language Processing, NLP)再一次成为人工智能领域最热门的课题之一,而ChatGPT所使用的“基于Transformer结构的大语言模型(Large Language Model, LLM)”也在一夜之间成为了几乎所有开发者争相研究的内容。
本篇将以理解发明Transformer结构的开山之作《Attention is all you need》为引,介绍自然语言处理模型的发展历史和相关知识。
正文
NLP模型发展历史
人类对自然语言模型的研究从上世纪50年代开始,当时人们对机器处理自然语言的主流研究方向是认为机器应该像人类理解语义那样,通过输入处理各种单词语法规则,将人类语言转换为机器可使用的语言来完成自然语言任务(Noam Chomsky, 1957)。直到70年代初Fred Jelinek首次提出了使用统计方法解决自然语言处理问题的统计语言模型(statistical language models),当年主流的统计语言模型有隐马可夫模型(hidden Markov model)、n元语义模型(n-gram model)、最大熵模型(maximum entropy model)等,这些模型与早年语义学(Lexicalism)推崇基于规则的语言模型不同,他们使用已有的数据基于统计模型来计算词语在当前上下文中出现的概率并以此预测自然语言结果,而这也是后来神经网络语言模型的基础。
所谓语言模型(Language model)就是给定前词预测后词的一种自然语言任务,人类第一个神经语言模型(Bengio, 2000)就首次使用了词嵌入(word embeding)与多层神经网络(Multi-layer Neural Networks)等技术来解决当时流行的n元语义模型面临的短上下文, 维数灾难等问题。此后涌现的新技术如多任务学习(Multi-task learning)(Collobert and Weston, 2008),Word2Vec(CBoW & Skip-gram)(Mikolov et al., 2013)也都为深度学习模型在自然语言处理领域发力奠定了基础。
从2013年开始,研究者开始大量使用深度学习网络构建NLP模型,最早被用来处理序列数据的RNN(Elman, 1990)以及为消除经典RNN模型梯度消失和梯度爆炸问题而出现的LSTM(Hochreiter & Schmidhuber, 1997)和GRU(Kyunghyun Cho et al., 2014),它们的基本原理都是通过将前文特征按顺序输入下一个单元从而实现依次输入处理序列信息的功能,具体参见这篇博文。除此之外还有CNN网络(Kalchbrenner et al., 2014)和Recursive neural networks(Socher et al., 2013)也都在自然语言处理上有所应用。
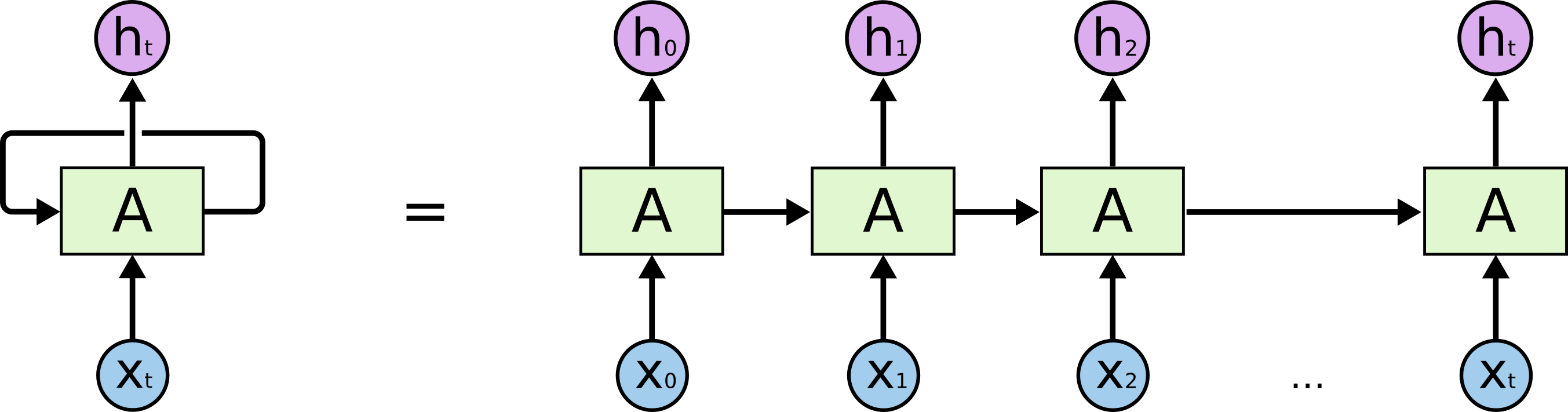
2014年,谷歌的三位学者提出Seq2Seq模型(Sutskever et al., 2014),其原理是使用一个RNN结构作为Encoder将输入的序列编码为一个含有序列信息的语境矢量(Context vector)然后用这个输出的矢量输入另一个RNN的Decoder中从而输出另一个序列信息。顾名思义,Seq2Seq的出现使得序列数据可以用于生成另一个序列,这弥补了深度学习网络此前只能进行语言模型或情感分析等简单任务的短板。但Seq2Seq结构本身并没有解决Encoder的输入序列过长时神经网络模型很难在一个单一的语境矢量中有效抓住所有有效信息的弊病,为解决这个问题,Transformer结构中最关键的注意力机制(Attention)被提出(Bahdanau et al., 2015),其原理是在Seq2Seq模型的基础上在Decode每一个目标单元时同时加入用来强调与该单元相关的Encoder单元语境的注意力模块,从而达到翻译每个目标位置时给予原文中单词不同权重的目的。
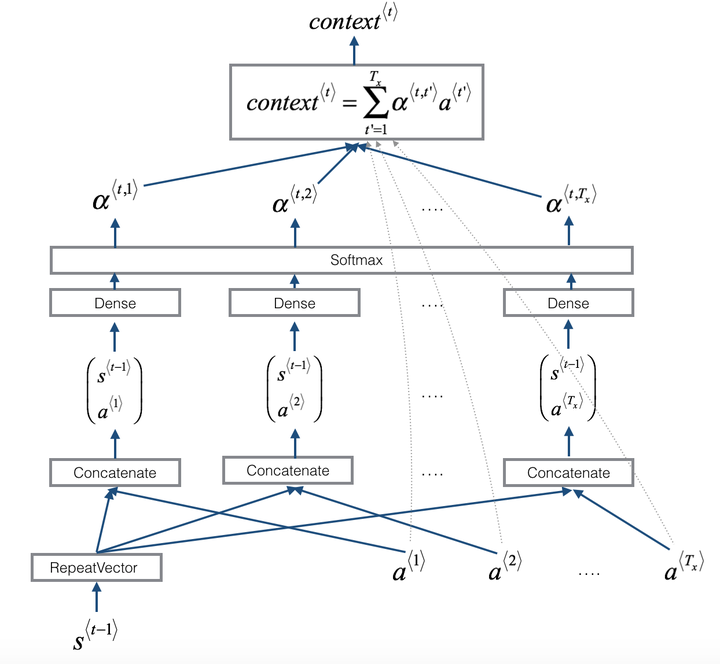
最终在2017年,谷歌机器翻译团队决定彻底抛弃RNN和CNN等传统结构,直接使用Attention机制架构多层自注意结构来完成机器翻译任务,并取得很好的效果(Vaswani et al., 2017)。到这里我们终于可以看看这篇文章到底讲了什么了, 本篇内容参考了很多著名大佬对Transformer的解读,包括Andrew Ng, Michael Phi, Jay Alammar, Sebastian Raschka, Prafulla Dalvi等,其中Andrew Ng和Michael Phi通过视频讲解或动画演示来介绍Transformer的大致概念和原理;Jay Alamar的博客将各种内容讲得非常细致,适合新手,推荐阅读;Sebastian Raschka和Prafulla Dalvi分别通过代码实现和数字实例解释抽象的结构,也可辅助理解,。
前置知识(Building Blocks)
自注意机制(Self-Attention)
Transformer结构中介绍的最重要的一个机制就是自注意机制,与RNN中的注意力只计算当前词与其他词的关联性不同,Transformer中的注意力为每一个可能的词引入了三个向量q(query),k(Keyword),和v(Value),每个可能的词都有独特的qkv三向量,而这三个向量分别由该词的词嵌入向量(word embedding vector)乘以从文本中训练而来的权重矩阵(Weight matrix) Wq,Wk, 和Wv计算得到。原文中词嵌入的维度是512,而权重矩阵的维度是512x64,因此两者相乘,每个词将得到维度为64的qkv三个向量。
如何理解这三个向量的作用呢?你可以将Query代表你要查询的词,Keyword代表输入中的其他词,对比q和k在向量空间中的相似度就可以知道两个词之间的关联有多大,将每个k(k1, k2, k3 …)与某个q(例如q1)的相似度使用softmax取最大的那一个,就可以知道每个k对于理解这个q1的权重有多少,然后将每个v分别乘以这个对应的权重取和就可以得到这个词在当前输入中的Attention值(在原文的例子里也是一个64维的向量)。而比较两个向量相似度最简单的方法就是使用点乘,越相似的两个向量相乘结果越大。原文中给出的公式是:
下图为原文图示对应上方公式的表达,其中Mask部分为Decoder部分特有,这里暂且不看;大写的QKV分别代表每个词的qkv向量组成的矩阵,该图中QKV中每行为输入序列中的一个词,列为上文提到的64维特征,也就是说假设输入是三个词的"I love you",那么QKV就都是3x64的矩阵。

因此上图中第一步的结果会是一个行代表query列代表key的3x3矩阵,其中的数字大小代表了每个qk pairs在64维空间上的相似度;第二步Scale是为了减小点乘的梯度波动而将上面3x3矩阵中的每个数字都除以空间维度的开方,因为点乘的结果可能使某个数字过大,这样后期计算softmax可能使这个结果的权重变成1其他都是0,所以这步操作也可以说是在分散注意力,在本例中这个值是;第三步softmax归一函数将每行的结果进行归一,大的增大,小的减少,经过这一步后3x3矩阵的每行的加和都会变成1,而每列就是该k对应q的在其他所有其他词中应占的权重,例如第1行第2列代表的就是"I"的query向量相对于"love"的k向量在“I love you”三个k向量中的权重,以机器翻译举例就是翻译"I"时应该对"love"分配的注意力权重;第四步将针对该q向量的每一个k向量的权重乘以其对应的v向量以重新获得针对每个输入词在64维向量空间上的重点分布,以矩阵来表示就是将此前3x3的权重矩阵乘以3x64的V矩阵,结果应该为3x64的矩阵,每一行都是一个q对应分配的注意力,也就是该自注意模块的输出结果。
多头注意力(Multi-Head Attention)
所谓的多头注意力其实简单讲就是多个上文的自注意模块的组合,原文中使用了8个头也就是将8个不同的Wq, Wk, Wv针对每个词计算出的QKV矩阵简单拼接在一起后通过点乘另一个与Wq, Wk, Wv一同训练得到的大权重矩阵W0的方法整合在一起得到最终的注意力矩阵。
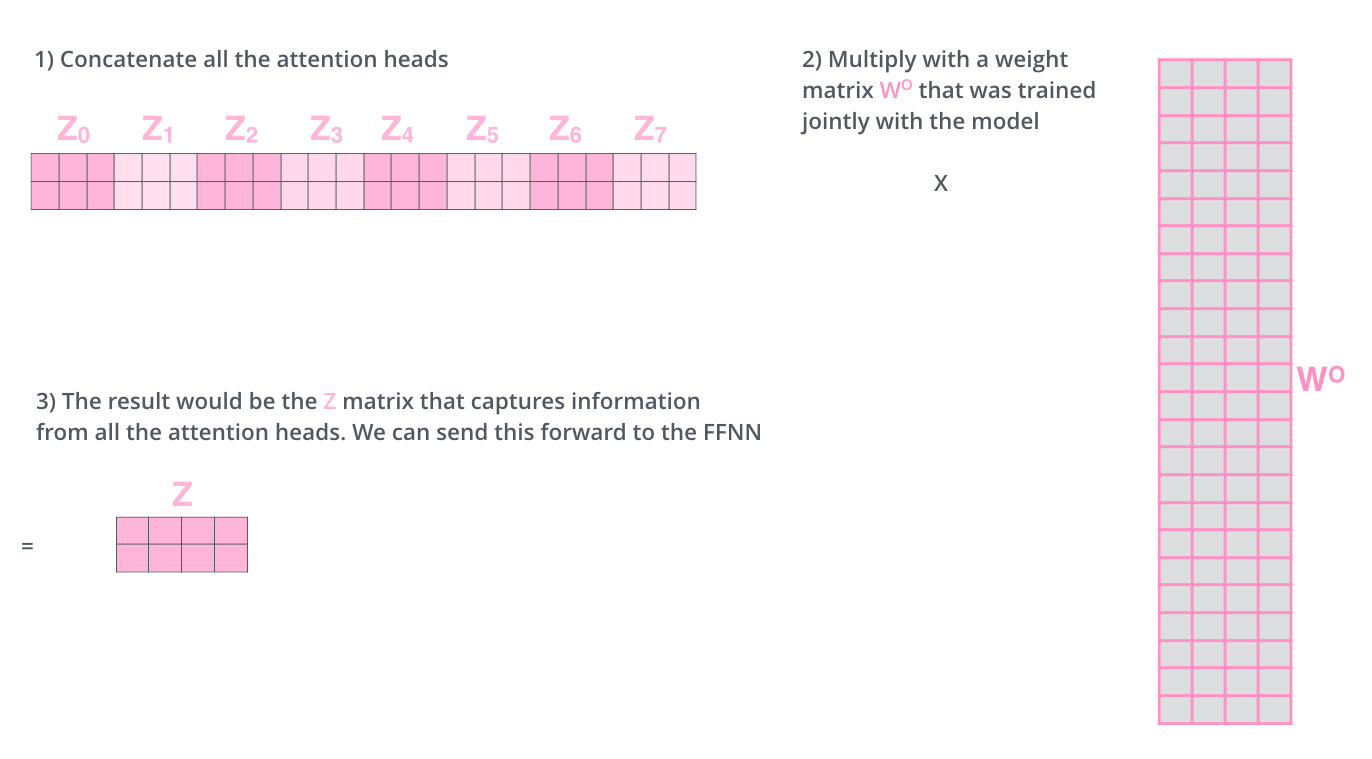
在我们的例子中,8个头拼接出来的矩阵是3x512(512 = 64 x 头数,也就是8),因此对应的权重矩阵W0为512x512,512列是为了将最终的乘积和重新整合成3x512的注意力矩阵从而与输入矩阵的规模统一,可以再次输入同一个单元。使用多头注意力的原因是避免单个注意力模块可能出现的某个词独占所有的注意力而导致理解不全面的情况,也就是说多头注意力拓展了模型完成自然语言任务时注意多个不同位置的能力,从另一个角度解释多头注意力就是从多个角度表示目标词的属性。
位置编码(Positional Encoding)
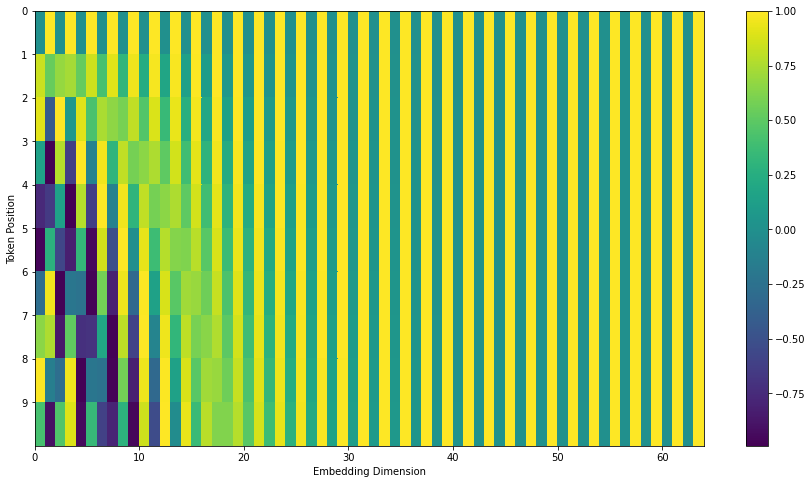
Transformer与传统RNN结构还有一个最大的不同就是自注意机制本身不会考虑输入词向量的位置信息,因为使用点乘求和也就是说每个词出现在矩阵的不同位置上他们计算出的结果不会有变化,但处理序列数据时位置信息一定是会对理解不同词有影响的。RNN结构通过循环引入上个时间点的结果,考虑了每个词出现的时机以及其会对理解下一个词造成的影响,而Transformer则是使用有固定规律的位置编码的方法引入输入中各词的位置信息。
其中pos是词在输入中出现的位置,i是维度。原文作者选用这个公式的原因是因为可以被表达为关于的线性函数,因此他们认为模型可以从这之中获得不同词之间的相对位置关系信息。其他模型中使用过通过学习获得的位置编码方法,他们也进行过实验发现二者效果区别不大, 且此方法可以计算超过训练数据最长句子的位置编码,因此选用这个可以直接计算的位置编码矩阵。将原文使用的位置编码方法使用图像表达如下:
残差连接(Residual Connection)
残差连接是为了解决深度学习网络中梯度消失(Gradient Vanish)问题而被提出,Transformer中也大量使用了残差连接。残差连接的实现简单来说就是将一些层的计算输出结果与其输入数据相加,这样保证网络不会在多次计算输出之后忘记数据最开始的样子。原文作者们除了使用残差连接以外还将其结果标准化(Normalize),即计算结果矩阵中每行的均值和标准差,以下面的公式计算标准化结果:
其中是均值,是标准差,和都是控制标准化结果的常量参数。
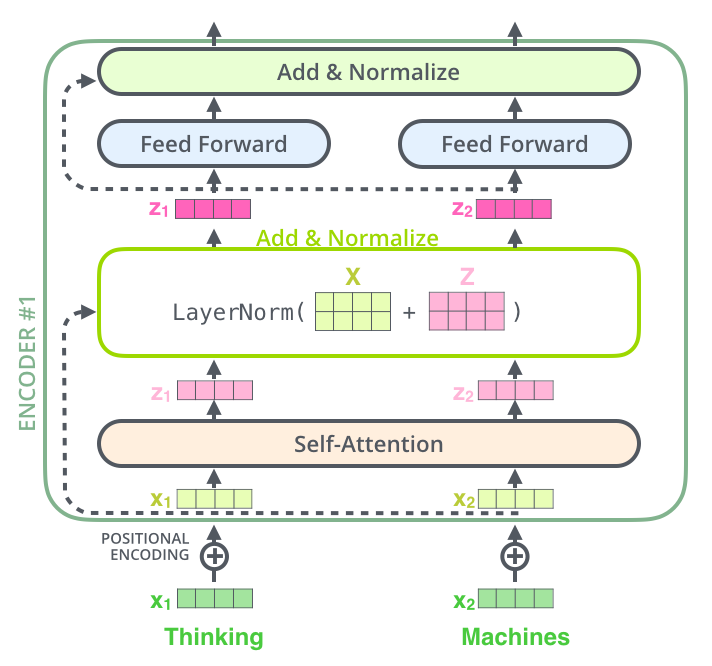
前馈神经网络(Feed Forward Neural Network)
为保证模型能够抓住更多非线性关系,加深网络深度和复杂度并使输出向量的不同维度之间保持信息互通,Transformer中还加入了许多全连接前馈神经网络(FNN)。原文中使用的FNN是中间使用ReLU激活函数的双层线性转换,用下方函数表示输入x与输出FNN(x)的关系:
其中就是ReLU激活函数的函数表达,与分别表示第i层的连接的权重和偏置,从公式可以看出该网络将第一层全连接结果使用ReLU函数激活后将结果继续输入第二层全连接并得到输出结果,原文中该网络输入与输出维度均为512,而中间层的维度为2048,对于不同词的FNN参数是相同的,但在结构中不同的FNN的参数都不同。
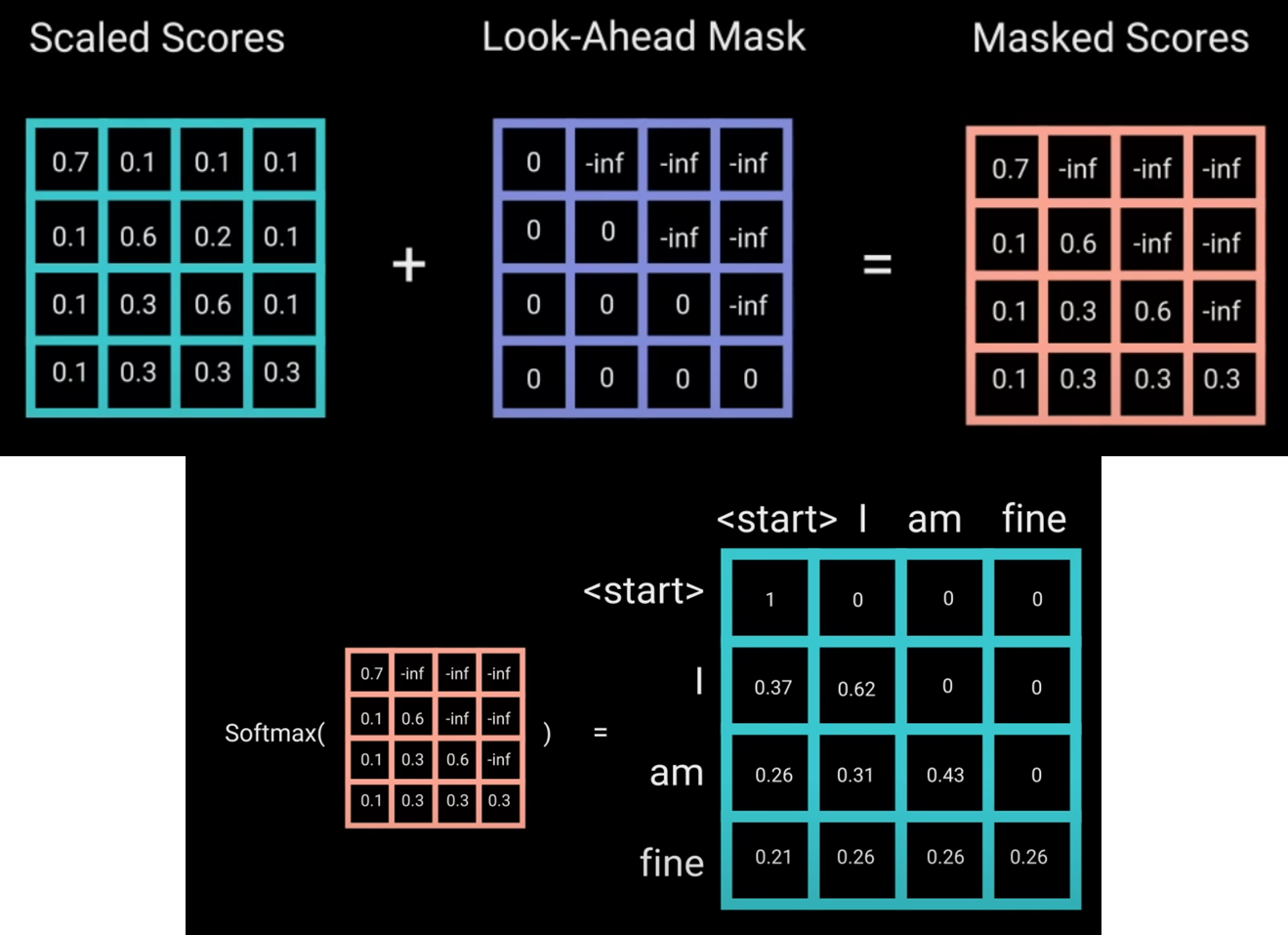
掩码注意力(Masked Attention)
就如前面提到的,原文中的注意力模块中有一个optional的Mask层,这个Mask只在Decoder中有在Encoder中没有,而之所以要在Decoder中加上这个Mask的原因是Decoder的任务是生成新的文本,而在之前提到的注意力机制中我们要计算每个key向量对某个query向量的注意力权重,但我们不能给予还没有生成的结果权重,因此我们需要将当前即将生成的query向量之后的key都mask掉,具体做法就是在的结果之上覆盖一个Look-ahead Mask,由此当前词之后词的key向量都会变成-inf,softmax函数激活后这些部分的权重就会是0,因此权重只会分布在之前已经生成的结果上。
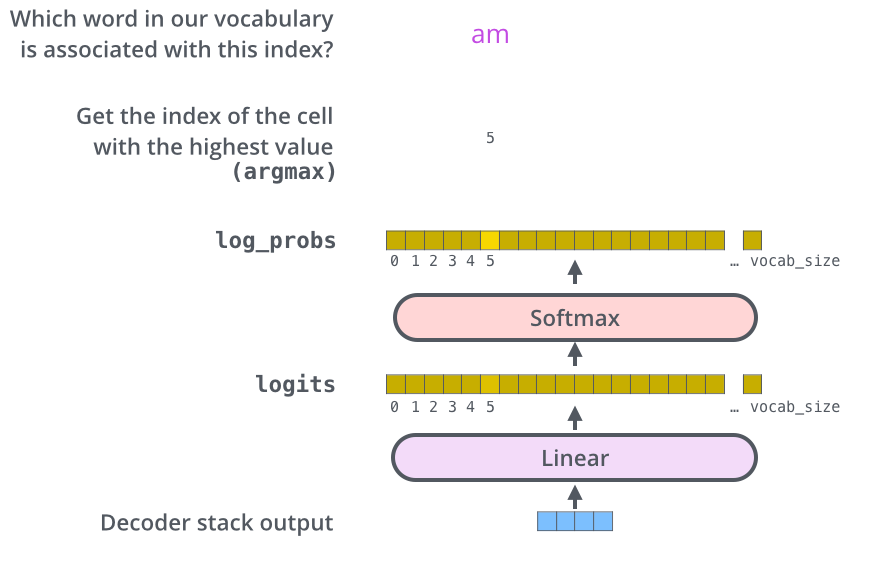
线性层(Linear Layer)
线性层也就是全连接层(Fully Connected Layer),需要这个结构的原因是我们最终需要将解码的数字输出为特定的单词,在这一层中的输出向量的每一个数字都代表一个已知的单词,例如我们的模型是翻译英语而我们已知的英语词有10000个,那么这一层Logits向量的长度就是10000。将Decoder输入这层线性层后对输出的Logits向量进行softmax激活,得到一个显示每个可能词概率的向量,概率最大的那个词就是我们最终选择的输出词。
Tranformer结构
到这里我们就拥有了组成Transformer结构的所有积木,回过头去看看整个Transformer的流程:
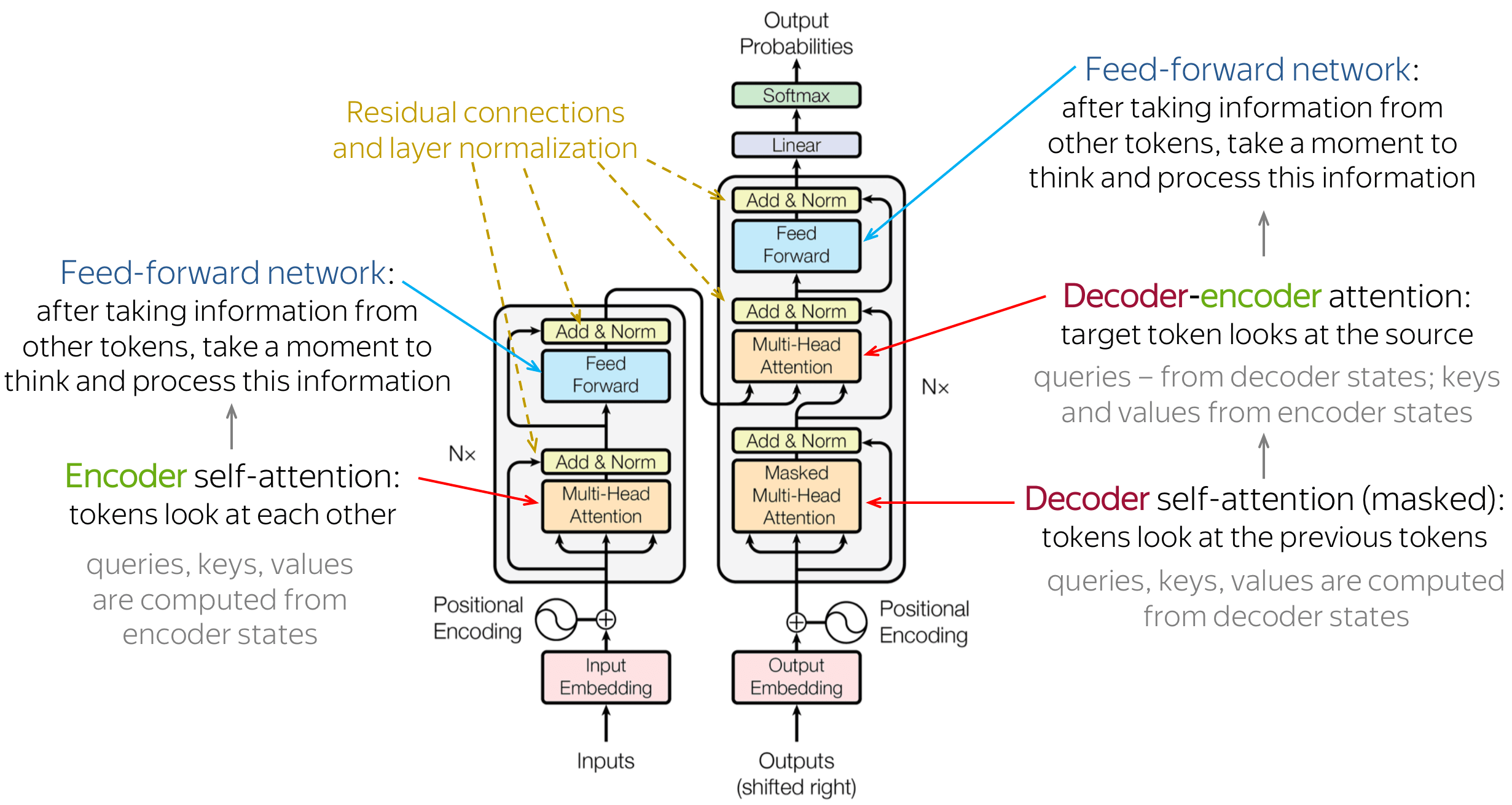
编码器(Encoder)
- 以将“I love you”翻译为中文为例,输入为3x512的词嵌入矩阵,矩阵的每行代表一个输入词的特征(representations)。
- 将位置编码加在词嵌入矩阵上,以使该输入包含不同词之间的相对位置的信息,输出依然为3x512的矩阵。
- 将上一步的矩阵放进第一个多头注意力模块输出3x512的注意力矩阵。
- 将第2步的输入矩阵和第3步的注意力矩阵结果加在一起进行标准化(残差连接),依然输出3x512的矩阵。
- 将第4步的矩阵输入全连接FNN中加强非线性联系,依然输出3x512的矩阵。
- 将第4步的输出矩阵和第5步的FNN输出矩阵相加标准化,并输出3x512的输出矩阵。
- 将第3-6步重复N次,原文中为重复6次,上一个次的输出作为下一次的输入,依次连接,最终结果还是3x512的矩阵。
解码器(Decoder)
- 解码器首先将已经输出的词转换为512维的词嵌入向量,由于没有第一个词,因此它的输入以一个
<BOS>(即Beginning of Sentense)为第一个输出,也即所谓的shifted right。假设已输出词m个,该处输入应为大小是mx512的矩阵 - 与编码器一样,在第8步的输出结果上覆盖一个位置编码,提供已输出结果的位置信息,输出mx512的矩阵。
- 将第9步的输出结果输入掩码多头注意力模块中,得到已输出的词语对当前已输出的词语的注意力矩阵,结果依然是mx512的矩阵。
- 将第10步的输出结果与第9步的输出结果通过残差标准化连接,输出mx512的矩阵。
- 将第11步中的Q矩阵拿出(此时为mx64的矩阵)的与第7步编码器的K,V矩阵(3x64)进行多头注意力计算,结果应为mx512的矩阵
- 将第11步输出与第12步的输出再次通过残差标准化连接,输出mx512的矩阵。
- 将第13步的结果输入与第5步不相同的另一个全连接FNN中,输出mx512的矩阵。
- 将13步的输出结果与14步的输出结果再次通过残差标准化连接,输出mx512的矩阵。
- 将第10-15步重复N次,原文中为重复6次,上一个次的输出作为下一次的输入,依次连接,最终结果还是mx512的矩阵。
- 将第16步的结果输入最终的线性层,通过softmax激活并找到下一个预测的词。
- 将第17步输出的结果加入此前已有的结果,重新输入第8步,直到17步输出
<EOS>(即End of Sentense)为止。
最后
在本篇中我回顾了NLP历史发展至Transformer的各个重大里程碑,并拆解Transformer结构中的各种创新设计及其意义,最后将整个Transformer模型的运作方式梳理了一遍。但此结构并不是NLP领域的最新进展,随后在此基础上发展出的BERT(Bidirectional Encoder Representations from Transformers), GPT(Generative Pretrained Transformer), 以及BERT结构的各种定向优化衍生模型等都在NLP历史上已经或正在产生改变世界的影响。下一篇NLP相关的文章就看看《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》吧。
[第29篇]





