[编程算法] 使用urllib和BeautifulSoup制作爬虫脚本收集公司公开信息的记录
序言
前段时间老板在看我司商业客户的数据统计结果时提出想要看一看我司现在商业客户的公司成立时间维度的分析,以此来推断新冠疫情是否对我司的一些统计指标造成了显著的影响。但我司数据采集时并没有向客户收集类似信息,而网上已经整理好的公司信息数据库一定是需要大笔花费才能买到的,好在我们只是需要像成立时间这样的基础信息,只要能找到可以查询到相应信息的公开网站,我们就可以使用Python写一个简单的爬虫脚本来系统性地收集这些数据。
这篇文章就介绍了我利用urllib和BeautifulSoup两个著名的爬虫库,从公开网站香港数据库集中扒出这些分析所需数据的小小的项目记录。
正文
准备阶段
当我们需要从网络上收集一些特定信息的时候我们要做的首先就是找到一个有这些信息公开网站,那么我开始这个项目的第一件事就是和我们负责商业客户的业务同事聊一聊他平时需要这些信息时通常去哪里看。同事给了我很多不同的选择,但其中有一些是香港政府的公司注册网站或其他收费的公司信息数据库平台,稍微浏览一下网站就知道这些网站通常都做了很严格的防爬虫措施。
最后通过一顿筛选我找到了这个号称是香港政府开放数据的数据库网站香港數據庫集,在这个网站中确实有许多政府相关的数据查询功能,其中就有这个页面可以根据公司名称查询公司信息。
研究网站
网站逻辑
要从网站上爬数据首先就是要把网站研究清楚,看使用什么方法最方便最快捷。首先搞清楚我们手上有的东西,事实上我们拥有的信息确实是非常的少,对于在我司购买商业保险的商业客户,我们除了他们的公司名和业务编号以外,并没有收集任何其他可以用于识别他们的信息。而这个网站可供用于引索的方法有四种:
- 通过公司名搜索,利用网站内建的搜索引擎链接公司名和公司独立信息页面。
- 通过公司注册编号,直接去往公司信息页面。
- 通过注册时间,每天都有一个单独的页面整理了所有这天成立的公司的清单,连接到公司信息页面。
- 通过注册地点,香港的每一个地区都有一个单独的页面整理注册在这个地区的公司清单,同样清单中包含每个公司信息页面的链接。
这其中后两种方法是非常绕的,对我们的目标也没有任何帮助(但不排除有其他需求时可以使用)。而前两种方法则分别有各自的利弊:
- 若通过公司名搜索有两个问题,一是可能无法搜到我想要的公司数据,而在爬虫运行的过程中我又很难判断哪些搜索成功,哪些没有;二就是这个搜索的方法会比较费时间,因为我需要将我的每一个公司名都单独搜索一遍,时间复杂度是O(n^2)。
- 通过注册编号搜索速度会快很多,因为公司的信息页索引编号其实就是公司注册编号,因此我们其实可以直接循环公司注册编号把整个数据库一锅端。但事实上现在这个编号数量已经到了三百多万,而我们要查的公司名总共也不过三万条。
最后很明显,只有通过公司名搜索这个方案可能可以较大程度上地满足我们的需求。
网站界面
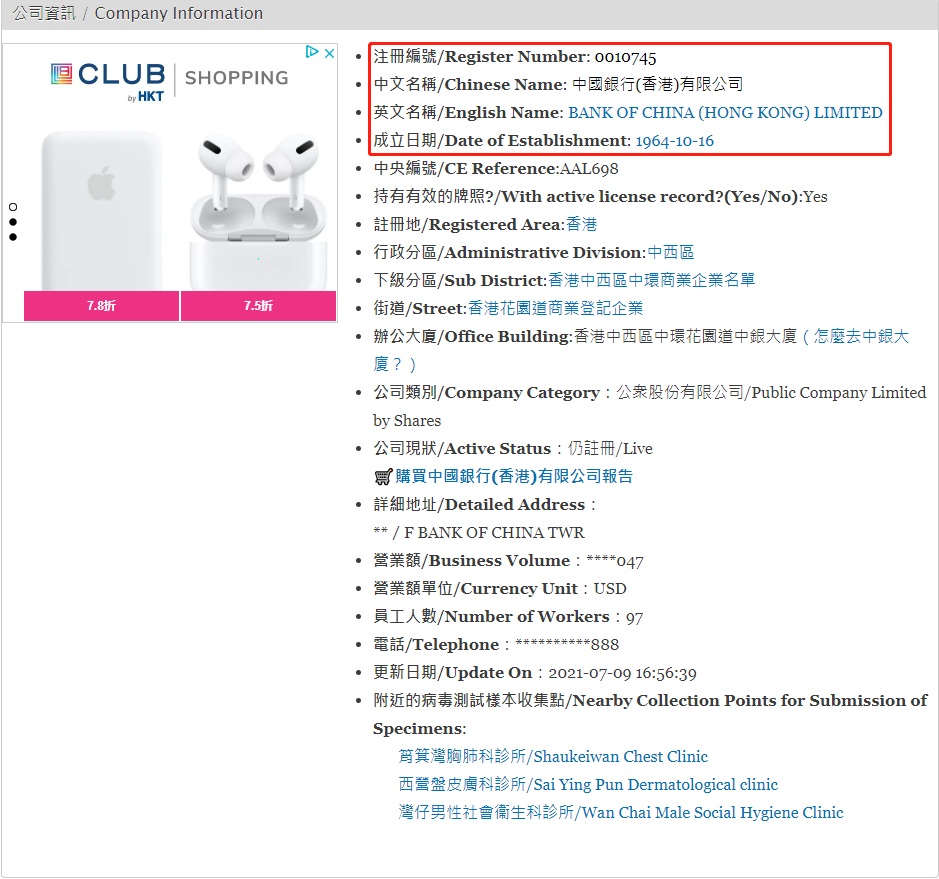
确定可行的方法后,就开始实际研究如何获得想要的信息,正常以公司名查询公司信息的话,应该在公司名称搜索的页面中输入公司的详细名称,然后在返回的结果中默认第一条是网站数据库中与关键词最相似的结果。点击这个搜索结果的链接就可以进到公司的实际信息页面。

在公司的信息页面中,则可以看到我们需要的成立日期等信息。我们之后要做的就是研究如何解析这一部分的html代码从而自动完成这两步操作并获取这些信息。
编写脚本
经过上一步对网站的研究后,我们的思路就很清晰了,现在只需要按刚刚的步骤逐步将人手操作的部分写成脚本。
搜索公司名
首先要明确我们的输入,就是公司商业客户数据库中的客户名,直接把这些名字拿出来做成一个csv列表,然后遍历即可。那么第一步我们先完成获取每一个公司的信息页面的函数。因此我们想要构建一个输入是公司全称,输出是网站查询到的第一条公司信息的网页链接的函数。
另外,虽然我们人手查询时需要在输入框中输入查询字段并点击查询,但实质上通过地址栏我们可以看到这一步操作其实就是向网站服务器发送一条带有查询字段的搜索请求,因此我们的脚本实际并不需要做这些互动操作。

通过研究网站的html结构,我写出来的代码如下:
1 | # 搜索页面的endpoint就是search?keywords=后加上搜索词的URL编码 |
需要补充的一点是,搜索到的链接使用的是相对引用,因此我们直接拿到href信息后还要把它和网站的根URL连在一起才是可以直接访问的页面链接。

处理搜索名称
在实际测试脚本的时候我发现我们公司的数据中,客户公司名称有时候可能因为一些缩写导致不能搜索到正确结果,其中最主要的原因就是将Company缩写为Co,Limited缩写为LTD。如果直接使用这些名称搜索的话就搜索不到相应的公司。所以我想的办法就是去掉所有这些缩写的CO或者LTD字段,直接只搜索前面有意义的名字。
代码上实现如下,输入是公司名的字符串,输出是截掉特定字的结果:
1 | def trun_name(companyname): |
这里需要注意的是因为这些缩写在单词中也不少见,所以不能直接replace(),否则会把单词中的这些组合也都一并删除了。
获取公司信息
现在我们假设通过前两步的环节,我们已经可以通过公司名称获得他的信息页链接了。接下来我们就要从这个返回的信息页中解析并提取我们需要的信息并整理。从下面代码的结构可以看到我们需要的信息被存在一个个的li标签元素中,而我们需要的信息都在这个元素的子元素中,一个自然想到的方法是使用BeautifulSoup的contents属性来获得每个li元素的子元素内容,然后根据表头信息把其中的内容分类装进字典中保存。
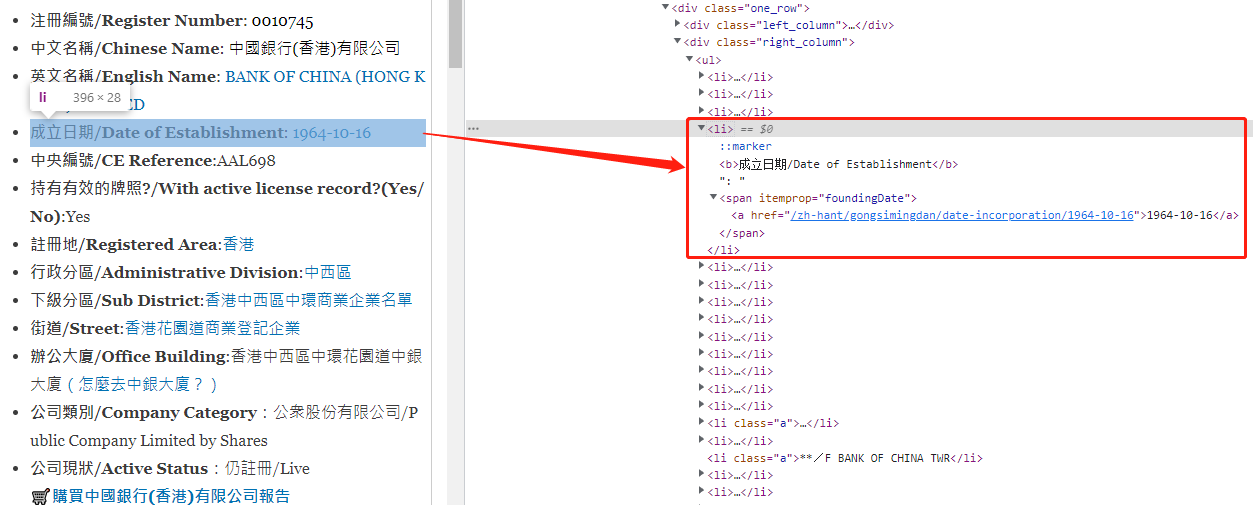
代码如下:
1 | def get_comp_info(comp_link): |
这段代码里值得说的一点可能就是转置字典的使用,其实就是为了让代码看起来干净一点,用这个方法代替了一溜if判断:
temp_info[switcher_dict[temp[0].text]]= temp[2].text
这一句话的意思就是将转置字典switcher_dict中对应键的值写入temp_info字典中,但如果字典中没有相应的键则会报错,这时使用try...except...就可以跳过那些不需要的信息。
读取和写入数据
有了上面这些函数,我们就已经可以从输入任意公司名字到返回包含所需的该公司信息的字典了。接下来就只需要把我们的公司名称列表循环起来就可以了:
1 | # 读取公司名字列表 |
读取和写入数据这一步我用了分开的方式,不直接在原本的公司名单文件中写入公司信息,而是只读取名字然后每次读取搜索后标记一下。这样就不至于如果中途程序中断不知道从哪里再开始。标记的信息每100次循环才存储一次,这样如果中断,需要重复的次数也不会超过一百次,得到的结果只需要对客户号去重就可以的到完整的结果。
到这里我们只需要运行这个脚本就已经可以开始慢慢收集数据了,我最后跑完整个三万三千条数据一共花了60个小时,平均每条记录需要运行5-10秒,而结果中大概有一万两千条是实际有数据的,足够我们数据分析的用途使用了。
Number of Companies searched: 58: 88%|████████████████████████████████▌ | 29366/33412 [55:30:09<5:20:53, 4.76s/it]
其他可能改进
虽然我们已经完成了手上数据的收集工作,但作为一个爬虫脚本,他还有一些可以改进的地方,就包括使用Proxy发送请求,以防止网站屏蔽IP,从而达到加速脚本的作用;其次还可以利用Windows scheduler的定时任务,固定时间定时获取新的公司信息情况。
使用Proxy发送请求
想要不被目标网站屏蔽IP的一个简单而有效的方法就是使用Proxy,这样对目标网站来说我们的发送的请求就是从不同来源发来,也就不会被发现我们在爬取数据。这个方法也可以使我们可以多开并行爬取,把爬虫速度提升很多。使用方法也很简单,可以利用PythonBroker实时获取有效的Proxy地址并添加在请求的头文件参数中即可。
参考资料:
增加实时更新的功能
之后因为我们可能需要按时更新我们的公司数据清单,但因为公司的成立日期不会有变化,因此为了减少我们每次的工作量,可以使用Python首先对比每次清单名称中新增的公司名,然后只查询这些新增的公司的信息,然后推入已有的数据库中。
至于定时脚本的方法,可以使用Windows系统自带的Windows scheduler完成定时运行脚本的步骤。
参考资料:
最后
在本篇中我介绍了我利用Python脚本收集一些公司没有的数据的项目的全过程,最后部分还有一些我在研究项目过程中有看到,且我认为可能对以后的类似项目有帮助的内容或方法,也记录在这里备用。
[第19篇]





