[数据分析]基于数据挖掘分类算法的续保价格优化模型记录
序言
所谓机器学习就是使用计算机算法让程序从已有数据中学习知识并应用,因此数据挖掘作为从数据中提炼规则的学科,其也是机器学习的最热门的分支之一。本篇缘起是因为老板想要一个可以预测保单续保与否的模型,我在收集数据准备模型的过程中想到了这个利用预测模型(Predictive Model)优化保险定价的指导模型(Prescriptive Model)。一言蔽之就是通过分类模型找出容易被保险定价影响的群体并建议放弃加价以获得其续保。本篇就记录一下这个项目的具体实现过程和表现评估。
正文
预测模型
项目第一步是构建一个可以预测续保结果的预测模型,本节会从随机森林模型的数据集构建、参数调整、表现评估等方便记录整个预测模型的构建过程。使用该模型进行实际运用的指导模型的建造和评估会在下一节详解。
数据收集
任何数据挖掘的第一步也是最重要的一步都是数据收集和整理,原数据的质量会直接影响到最后模型的表现。我在做这个项目的时候只用到了公司数据库的数据,而且由于不同险种的可用数据不太一样,我为了提高预测模型的准确性先选定了研究“家居保险”,因此我首先和业务的同事们开会讨论了一下他们认为的可能对家居保险续保有预测效果的保单特征,例如代理的渠道和佣金,顾客的年龄、性别、忠诚度,保单信息中的楼龄、付款方式等等。我具体收集的一些特征如下:
| 分类 | 数据 | 描述 |
|---|---|---|
| 保单信息 | 原始保费 | 家居险的原始保费与其保额及单位面积有关,因此认为可以一定程度上反应客户的财务水平 |
| 保费增长 | 计算得出的续保保费与续保前保费的增长率,是本数据集中公司在续保过程中唯一可以控制的因素 | |
| 理赔数量&理赔金额 | 反应客户的理赔方面的特征,因为认为理赔情况可能影响客户的续保决定 | |
| 产品相关信息 | 一些仅与家具险相关的数据信息,例如客户是否选购特殊保障条款,所保单位楼龄的分层等 | |
| 代理信息 | 代理渠道 | 不同的代理商提供给客户的服务体验不同,可能导致续保决策的差异 |
| 佣金水平 | 不同的代理商的佣金水平的差异可能反映至代理商对客户的态度区别 | |
| 客户信息 | 客户年龄 | 根据本项目开始前的探索性数据分析得知,客户年龄与其续保行为具有较高的相关性,年龄越大的客户越倾向于续保 |
| 客户性别 | 性别被认为是客户分层的重要维度,但需要注意该特征的使用具有敏感性,不应在会体现出性别区别对待的模型上使用该特征 | |
| 客户忠诚度 | 选择两个信息用来衡量客户的忠诚度,分别是客户持有我司的总保单数和客户与我司合作的总年数 |
基于以上这些数据维度,我收集了公司2021年经过续保流程的可续保家居保险保单,并且将续保结果(Lapsed or Renewed)作为数据集的目标分类。
数据清洗
总体来说由于数据都是来自于公司自己的数据库中,因此没有太多需要清洗的地方,主要值得说的就是对于缺失值的处理方法。由于公司没有特别收集家居险客户的个人资料,因此客户的性别与年龄数据都是来自于其购买其他如意外险等需要年龄性别信息的投保资料,这也导致客户信息的这一块有非常多的缺失值。下图中是我收集到的保单的性别与年龄分布,这两个信息都有多于一半的保单有信息缺失。
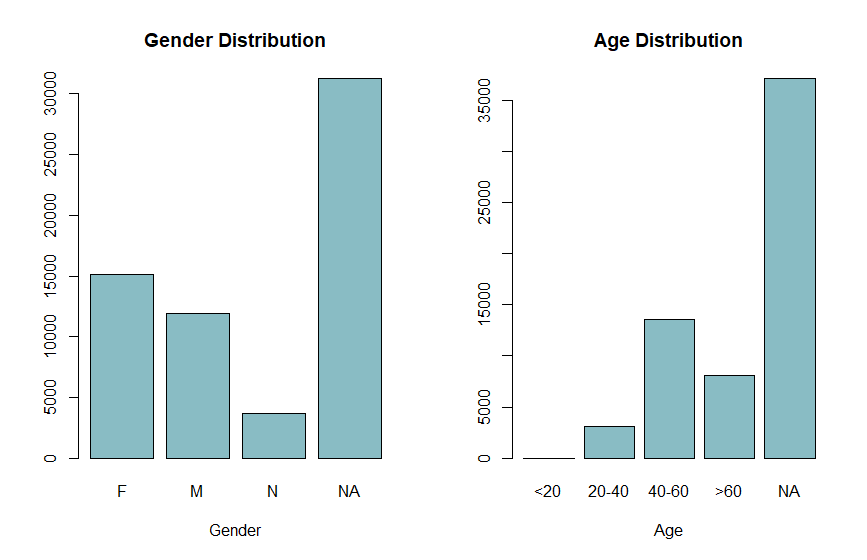
但因为这两个特征从经验判断都是对于续保决策的预测相当有帮助的,而同时由于大量保单都有系统性缺失数据,因此我既不能舍弃掉这两个特征同时又不能直接删除或估算(Impute)缺失值。同时由于这些值是系统性缺失,所以我可以合理假设缺失值本身也带有一些信息(由于某些原因这些客户没有提供个人信息)。因此我的处理方式就是将缺失值加入水平值。代码上实现也很简单:
1 | # 使用addNA将缺失值加入因子特征的水平值 |
需要注意的一点是虽然使用addNA()公式就已经把缺失值加入了因子变量的水平值中,但还需要进行第二步对水平变量赋值的操作,否则R的RandomForest算法会错误处理这些NA变量,导致报错。具体可以参考这个问题。
处理不平衡数据
由于我们想要预测的目标分类是某个保单的续保结果,但我司家居险的保单续保率实际达到95%以上,这也就导致我们的数据一定是非常不平衡的,而我们想要预测的却是小数据量的部分标签,如果不加处理就直接以这个比例训练模型的话会导致模型在预测小数据量标签时的表现严重欠拟合。
在简单对比尝试了普通的欠采样(Undersampling)、过采样(Oversampling)与SMOTE方法后,后发现SMOTE训练出的模型效果最能满足我们所需的较高精确度(Precision)。我们不需要将所有不续保的保单预测出来,但我们希望在我们预测会不续保的保单尽可能不要出错,因为每多预测错一个保单就意味着我们要多付出一份不必要的成本,不同处理方法的训练效果会在后面的模型评估中展示。数据最后处理的处理效果如下:
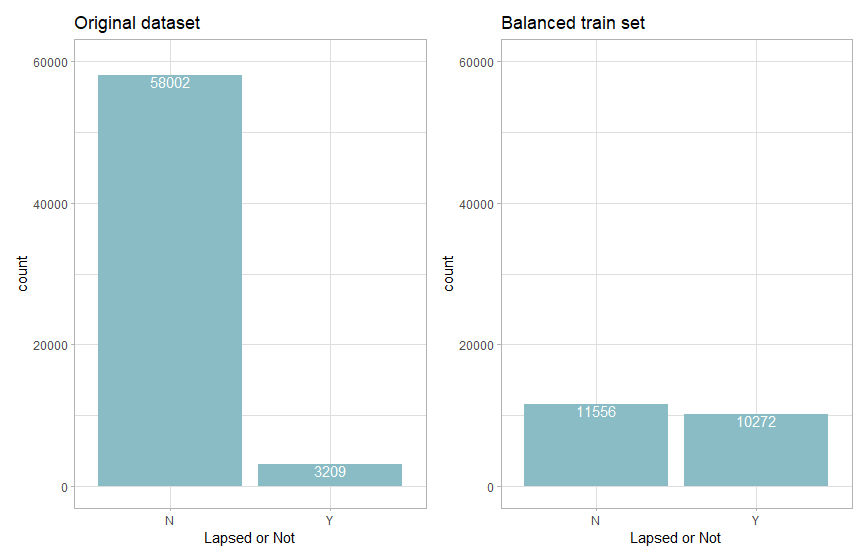
代码如下,其中:
1 | # ROSE包提供欠采样和过采样方法,performanceEstimation提供SMOTE方法 |
随机森林参数调整
随机森林的算法本质是一个决策树的投票模型(ensemble model),其做法是从所有数据中随机抽取一部分样本 (2/3)作为训练集,并随机抽取这些样本的特定数量的特征训练决策树。每个单个决策树默认使用基尼不纯度(Gini Impurity)作为信息增益(Information Gain)的衡量方法,在每个选出的特征值中找出分类目标标签获得最大信息增益的特征作为当个节点的分支,直到将所有抽选的特征分完(也就是让决策树不剪枝完全生长)。以同样的方式随机生成指定数量的决策树,然后使用这些决策树对每一个记录分别分类,以投票的方式决定该记录的最终分类。
随机森林的好处就在于其使用随机数据和随机特征训练模型,使其相较普通决策树泛化(generalization)效果更好,过拟合风险小。而其弱点在于分类过程不透明,与深度学习模型相似属于黑箱模型(Black-box)。因此通常如果我们想要通过数据挖掘算法获取一些数据间的关系和规则时,可以使用决策树算法来揭示。但如果像本项目这样需要一个尽可能准确的预测模型,则可以使用随机森林模型。
在我们使用R的RandomForest包进行随机森林模型训练的时候有两个参数会较大的影响我们的模型表现,一个是生成的决策树数量ntree,一个是随机选取的特征数量mtry。我在这里将两个参数在合理的范围内测试并使用AUC(Area Under ROC Curve)作为模型表现的指标选出了最优的参数分别为ntree=300, mtry=6。
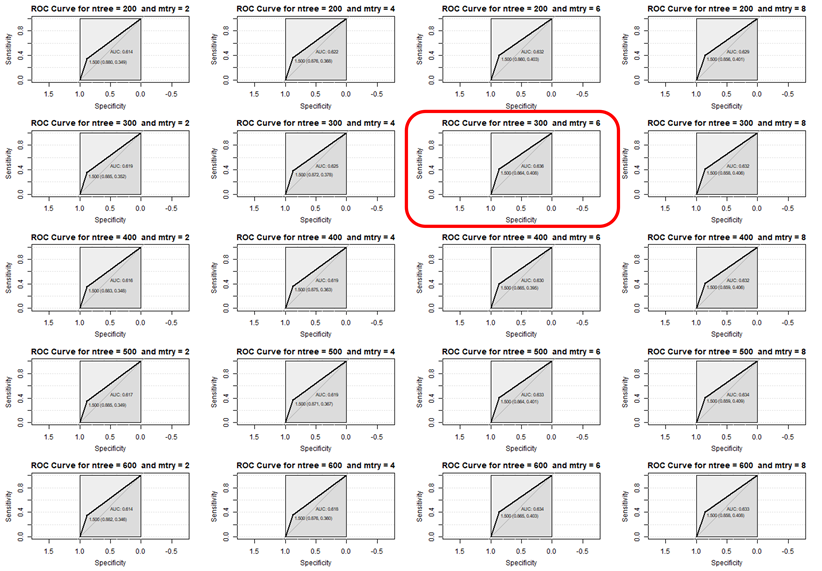
代码如下:
1 | # 分别尝试ntree在200-600区间,mtry在2-8的区间时模型的AUC变化 |
预测模型表现评估
使用测试集对不同训练集训练出的随机森林模型进行表现评估,发现SMOTE调整后的训练集最符合我们高精准度前提下的高正确率的要求。混淆矩阵(Confusion matrix)对比如下:
| 预测标签 | |||||||
|---|---|---|---|---|---|---|---|
| 实际标签 | SMOTE | 欠采样 | 欠采样+过采样 | ||||
| Renew | Lapse | Renew | Lapse | Renew | Lapse | ||
| Renew | 9,963 | 1,649 | 7,264 | 4,348 | 9,212 | 2,390 | |
| Lapse | 382 | 249 | 184 | 447 | 292 | 349 | |
精准度与正确率的对比如下:
| SMOTE | 欠采样 | 欠采样+过采样 | |
|---|---|---|---|
| 精准度(Precision) | 13.1% | 9.3% | 12.7% |
| 正确率(Accuracy) | 83.4% | 62.3% | 78.1% |
| 回归率(Recall) | 39.5% | 70.8% | 54.4% |
从上面这些评估中可以看出来即使是表现最好的SMOTE数据集训练出的的预测模型,在预测不续保保单时精准度也非常之低,根本原因就是在于实践中续保保单数量远大于不续保保单,而我们的数据集中没有包含足够的区分这两者的信息(因为客户不续保的根本动机可能性非常多,例如可能被其他保险人接触或出于其本身经济考虑),因此预测效果一定不会非常好,只要高于阳性标签比例的5.1%就说明已经是有用的预测模型。
一个更好的消息是我们实际上关注的是我们可以通过调整保费来留住的客户,而这些被标注为不续保的1,898个客户中实际可能并不全是因为保费变化而被标注为不续保,下一节我会介绍一下我基于这个预测模型提出的指导模型的用法,以及其价值评估。
指导模型
变量重要性
虽然随机森林模型本身是一个黑箱模型,但我们其实也有办法评估不同变量在预测中的重要性(Importance)。其基本思想就是根据移除不同的特征后模型预测准确度的变化大小来评估每个特征变量的重要性,而从下面这张图中我们除了知道客户忠诚度是准确预测其续保决策的最重要的变量之外,还知道保费变化也对客户的续保决策有较重要的影响。这也是我们可以使用这个预测模型来分类对保费变化敏感的客户并针对性调整保费变化决策以增加总体续保率的理论基础。
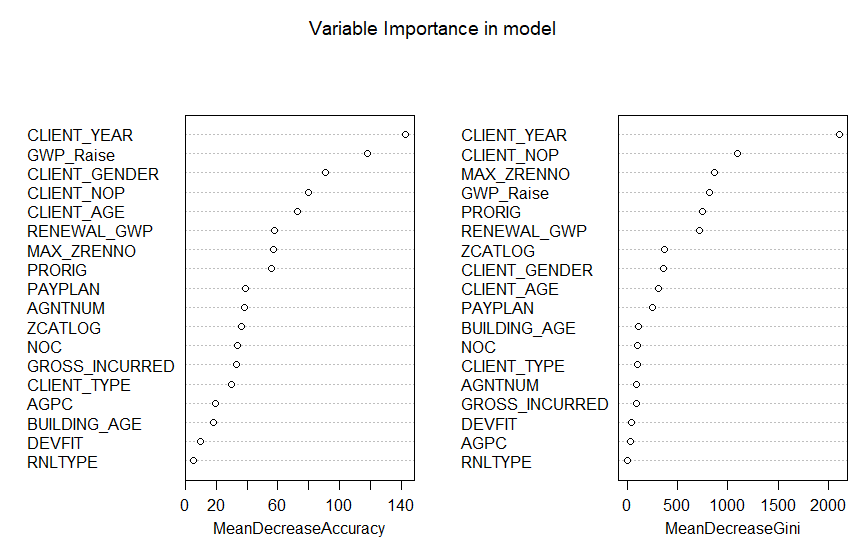
模型架构
简单来讲我想到的指导模型的使用方法就是通过调整测试集中预测不续保保单的保费增长率来确定该保单的不续保决策是否由于保费增长影响。若预测模型认为保费增长率调整后预测结果可从不续保转为续保,则说明模型认为该保单受保费增长影响而不续保。模型流程图如下:
指导模型评估
我们依然可以使用我们最早分出来的测试集来测试这个模型的表现,首先看一看测试集中这个模型对续保率的增益和成本:
| Label Changed | Label NOT Changed | |
|---|---|---|
| TP | 77 | 220 |
| FP | 215 | 1,393 |
| TN | 2 | 9,981 |
| FN | 0 | 355 |
在上面这个表中,我对比了不同预测结果与指导模型划分的“价格敏感”保单的分布。其中Label Changed列便是在上方指导模型中被标记为“因受保费增长影响可能不续保”的保单。也就是说,在这一列中被预测为Positive的保单就是我们实际操作中建议免除保费增长的保单。而这其中的FP(False Positive)则是被标记为不续保但实际即使保费增长也会续保的保单。
这也即是说在我们的测试集中,这77笔TP保单的保费会成为模型实践后的收入(因为阻止了这77笔保单的不续保),而这292笔Positive保单原本应该涨的保费则是该模型的成本(放弃了292个保单的涨价)。而测试集中这292笔保单的平均涨价保费是90港币,77笔TP保单的续保总保费是103,472.6港币,平均至292个保单相当于每放弃90港币的涨价预期可以获得354.3港币的保费收入。
而这77个TP保单占所有652个不续保保单的12%,即是说我们的模型预期可以使12%本会不续保的保单续保,将整体续保率从94.7%升至95.3%。
代码如下:
1 | # 将原测试集的预测结果记录下来 |
使用聚类分析对预测结果优化的尝试
有一个我在优化模型时失败的尝试我觉得也值得记录一下,当时的想法就是想看一看能不能用聚类分析(Clustering analysis)的方法找到一些FP与TP保单中可能被随机森林模型忽略的信息,因此我尝试在预测模型预测阳性的保单上使用K-means Clustering并看一看是否有明显FP数量大于TP的聚类。结果举例如下:
| Clusters | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| FP | 18 | 2 | 20 | 147 | 34 | 186 | 12 | 27 | 49 | 245 |
| TP | 7 | 1 | 6 | 63 | 20 | 94 | 9 | 24 | 30 | 90 |
可以看出来没有聚类能明显区分这些FP和TP的保单,因此可能确实说明我们的数据集中的信息已经不足以更细地区分这些保单了。
最后
这个模型只是最初版对于项目可行性的尝试,很多对数据集的处理 (特征选择,使用numerical或categorical变量等)或模型选择(使用随机森林、神经网络或支持向量机分类等)都没有太过深入以追求最好的效果,同时保费增加的调整也可以根据实际情况更细分层(例如分为增长5%、增长10%等)而减少额外的成本,但到这里其实我们已经从一定程度上获得了可行的结果。之后在模型实际投产前我可能会需要在这个基础上使用Weka更深地探究模型的最优化。
[第17篇]





