[数据分析]常用数据库类型对比介绍
序言
由于我本科并不是学的计算机,所以其实很多计算机基础的知识我都不太了解。最近在做一些数据库相关的工作的时候发现公司数据库系统使用的IBM DB2在操作和逻辑上似乎和之前用过的Oracle有一些差异,因此也发现我原来连这些不同数据库之间到底有些什么联系或者差异都不知道。所以今天想要系统地了解一下不同的数据库之间的关系和差异。
正文
接下来我会先从数据库的基本特性的概念开始介绍,因为正是因为这些特性很多不可以兼得,所以才衍生出各种各样不同的数据库类型。之后再看一看各个有名的数据库各自有什么特点,最后再讲讲公司用的DB2数据库在实际操作中与Oracle到底有什么细节上的区别和联系。
影响数据库选择的因素
知乎的民工哥在他的回答中列出了几项影响数据库选择的因素,因为这些因素可能不能同时达成,或者达成有额外成本,因此不同的数据库可能为满足不同的生产需求对这些因素的实现程度和效率都有区别。他的总结是下面这些点:
数据量:是否海量数据,单表数据量太大会考验数据库的性能数据结构:结构化 (每条记录的结构都一样) 还是非结构化的 (不同记录的结构可以不一样)是否宽表:一条记录是 10 个域,还是成百上千个域数据属性:是基本数据 (比如用户信息)、业务数据 (比如用户行为)、辅助数据 (比如日志)、缓存数据是否要求事务性:一个事务由多个操作组成,必须全部成功或全部回滚,不允许部分成功实时性:对写延迟,或读延迟有没有要求,比如有的业务允许写延迟高但要求读延迟低查询量:比如有的业务要求查询大量记录的少数列,有的要求查询少数记录的所有列排序要求:比如有的业务是针对时间序列操作的可靠性要求:对数据丢失的容忍度一致性要求:是否要求读到的一定是最新写入的数据对增删查改的要求:有的业务要能快速的对单条数据做增删查改 (比如用户信息),有的要求批量导入,有的不需要修改删除单条记录 (比如日志、用户行为),有的要求检索少量数据 (比如日志),有的要求快速读取大量数据 (比如展示报表),有的要求大量读取并计算数据 (比如分析用户行为)是否需要支持多表操作
关系型数据库和非关系型数据库(参考资料)
关系型数据库(Relational or SQL)和非关系型数据库(Non-relational or NoSQL)是目前数据库系统的两个大类,虽然目前工作中有机会接触到的主要都是关系型数据库,但作为新兴的大数据工具以及与关系型数据库功能互补的非关系型数据库,NoSQL现在在数据库业界的势头也非常之猛,因此这里也简单了解一下。
关系型数据库(Relational DBMS)
关系型数据库的特点顾名思义就是用相互联系的表(tables)来存储数据,结构化查询语言(Structured Query Language, 也即SQL)是这套数据库系统的核心,人们用这套语言来管理关系型数据库,也因此这类数据库就被称为SQL database。关系型数据库需要提前定义模式(Schema),也就是说数据库中存储的数据的属性(attributes)及其数据格式需要被严格定义,而每条数据(records)都在相应属性上有一个值,也就是说不同数据之间的关系非常明确。
可扩展性(Scalability)
关系型数据库一般只能纵向扩展,也就是说在同一个服务器中增加更多算力和空间(CPU,GPU,RAM等),而如果要将关系型数据库分布在多个服务器上的话则需要改变数据结构等复杂操作。
性能(Performance)
关系型数据库在处理中小型数据规模时性能较好,如果在数据库中加入索引(index)还能更加增强数据库查询(QUERY)和连接(JOIN)的效率。但如果数据量和用户访问量更大时,这类数据库性能就可能不足。
安全性(Security)
由于数据高度结构化,关系型数据库的安全性保障不需要太麻烦。由于关系型数据库拥有ACID四大特性,分别是原子性(Atomicity),一致性(Consistency),隔离性(Isolation)和持久性(Durability)。这几个特性使得储存在关系型数据库中的数据有较高的完整性(Integrity),这类数据库非常适合应用在金融电商等对数据完整性要求较高的应用场景。
非关系型数据库(NoSQL)
非关系型数据库是各种非表结构数据库的共称,这类数据库有一些代表性的模型:
文档类(Document-oriented):用JSON格式的文档存储,提取,管理数据。代表有MongoDB。键值类(Key-value):这类数据库通常有一个哈希表,表中有一个特定的键和一个指针指向特定的数据,也就是说每一个值都与一个数据一一对应。代表有Redis。图形类(Graph):使用图结构存储数据,将数据以边缘节点的形式存储,其中节点(node)代表的是数据,而边缘(edge)则代表数据之间的关系,这类数据库主要用来构建数据间的关系图谱。代表有Neo4J。列存储类(Wide-column):将数据存储在非常多的列中,每一条数据都由键指向可能不同的列中,也即每条数据都可能拥有不同的属性。代表有Cassandra。
可扩展性(Scalability)
非关系型数据库在数据量和访问量增加时,可以通过横向扩容(即增加更多服务器)来扩展容量。这些服务器共享数据,每个服务器仅储存一部分数据,这样每个服务器需要处理的平均访问次数也会减少。由于他们没有结构性的表,因此扩展不需要额外的操作。
性能(Performance)
由于非关系型数据库的分布式特性,其性能普遍较高。这类数据库可以无限制地储存各种类型和格式的数据,改变已有的数据格式也会比较方便。
安全性(Security)
安全性是非关系型数据库的一个主要弱点,更高的自由度就是以数据的完整性为代价。
主要关系型数据库对比
由于非关系型数据库目前不在我的业务范围内,我就侧重对比研究一下关系型数据库的几个代表:Oracle, MySQL, MS SQL Server, PostgreSQL和IBM DB2。DB-Engines网站对各大数据库的流行趋势针对其在公共网络(如搜索引擎,开放职位描述,技术论坛等)上的出现频次进行打分排名:
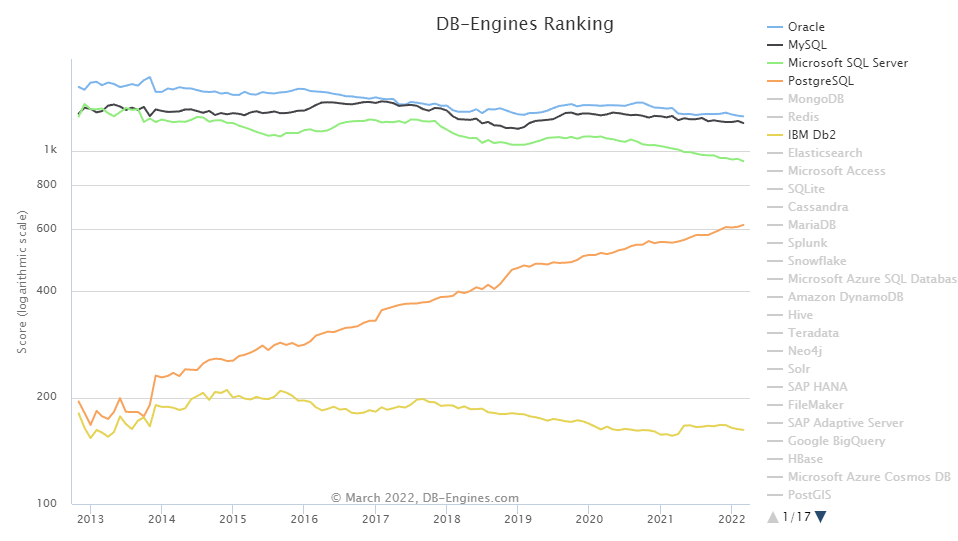
可以看到尽管有下降趋势,Oracle, MySQL和MS SQL Server依然有绝对的热度,而相对的PostgreSQL近年趋势猛升,而IBM DB2作为关系型数据库的开拓者,其在近年的主要客户群体仅集中在金融行业(以银行,证券,保险,基金公司等,行业代表有花旗,渣打,汇丰,摩根斯坦利以及我司等,哈哈),因此在大众的讨论热度比其他数据库要低。
Oracle
大名鼎鼎的甲骨文公司,说他们开发的数据库管理系统是业界最著名应该也不会有太多人有异议。其目前支持将各种关系型及非关系型数据库在同一个数据库中管理。基本支持所有主流操作平台,性能好,功能强,稳定性好,安全性强但价格昂贵(免费版功能有限)。目前甲骨文开发的主要关注点在云计算方面。
其主要优点包括创新力强,技术支持及文档资源完备,具备存储处理海量数据的能力。主要缺点就是贵(标准版单价17,500美元,企业版单价47,000美元),且匹配其高性能其也需要较高的硬件和人员支持才能稳定运行。
如果你有数以亿计的OLTP或数据仓库数据需要储存和处理且预算充足的话,Oracle是一个可以考虑的选择。
MySQL
MySQL如今也是甲骨文公司的明星产品,是现在最知名的关系型数据库之一,与Oracle不同,MySQL是开源的。MySQL由C和C++编写而成,是网页开发组合LAMP的一大组成部分,其名字LAMP分别指Linux(操作系统), Apache(网页服务器), MySQL(数据库)和PHP(脚本语言)。可以在大部分主流平台运行。
其主要优点包括免费安装,使用简单,结构不复杂,易于调试且支持云服务。主要缺点在于其底层代码逻辑不适于大型数据库,非完全开源导致一些特定功能不能被免费实现,另外有一些SQL标准操作不被MySQL支持。
如果你只是想做一些小型的网页数据库,或者是数据量不大,复杂度不高的数据管理系统。
MS SQL Server
MS SQL Server是微软早期为与IBM在数据库领域竞争而开发的关系型数据库产品,它的主要特点继承了微软的发家秘诀,即可视化,易操作但只能在Windows环境中运行。操作MS SQL Server数据的语言是在SQL标准上发展的Transact-SQL语言。
其主要优点包括针对不同应用场景的涵盖不同功能的各种版本,提供各种商业所需的数据相关附加服务,丰富的文档和社区支持以及云服务等。主要缺点包括贵,支持平台单一,调试复杂。
如果你的的公司订阅了微软的其他产品服务,选择MS SQL Server可能是个不错的选择,微软对其不同产品之间的互动集成做得还是不错的,有助于增强用户体验。
PostgreSQL
PostgreSQL是开源的对象-关系数据库(object-relational database),其相较其他普通关系数据库的差别在于用户可以在PostgreSQL中编程实现自定义对象以实现存储更复杂的数据结构。PostgreSQL与MySQL有许多共同点并在此之上加强了扩展性与合规性,也因此它可以适用于各种不同的数据规模。可以在微软, iOS, 安卓等平台上运行。
其主要优点包括可扩展性高,支持JSON, XML, H-Store等用户自定义的数据格式,拥有易于使用的第三方增强工具,完全开源等。主要缺点在于其文档没有统一标准,且数据库缺少完整性检查工具。
如果你希望自己的数据库存储格式可以定制化并实现一定的数据分析功能,PostgreSQL可以是较好的选择。其在金融电信行业使用较多。
IBM DB2
尽管现在的热度不高,但DB2被认为是关系型数据库的开山鼻祖。其由C和C++编写,可以在UNIX,Linux,Windows服务器版本等多种环境下执行。
DB2的主要优点在于他经过多年大量的实用测试没有出过大的问题,是一个非常值得信赖稳定的的数据库系统,其适用大规模数据且性能也较高。主要缺点可能包括文档和用户界面陈旧对新手不友好,操作较为复杂。
目前DB2的主要用户都是金融公司,这些公司创建数据库比较早,但对技术变革不敏感,且依赖数据库的安全性和稳定性,因此留存为DB2用户。
DB2与Oracle SQL语法差别(参考资料)
由于我自己学的是Oracle的语法,但现在工作需要使用DB2的语法,因此找了一下网上大神们整理的这两者的区别汇总,发现邬兴亮大神的总结就是我想找的:
数据类型转换函数
| 整形转字符 | 字符转整形 | 字符转浮点 | 浮点转字符 | 字符转日期 | 字符转时间 | 日期转字符 | |
|---|---|---|---|---|---|---|---|
| Oracle | to_char(1) | to_number(‘1’) | to_number(‘1.1’) | to_char(1.1) | to_date(‘2007-04-26’,‘yyyy-mm-dd’) | to_date(‘2007-04-26 08:08:08’,‘yyyy-mm-dd hh25:mi:ss’) | to_char(to_date(‘2007-04-29’,‘yyyy-mm-dd’),‘yyyy-mm-dd’) |
| DB2 | char(1) | int(‘1’) | double(‘1.1’) | char(1.1) | date(‘2007-04-26’) | to_date(‘2007-04-26 08:08:08’,‘yyyy-mm-dd hh25:mi:ss’) | char(date(‘2007-04-29’)) |
| 兼容写法 | cast(1 as char) | cast(‘1’ as int) | 无 | 无 | 无 | 相同 | 无 |
Where条件弱类型判断
在Oracle中使用"Where 字符型字段 in (整型)"是允许的,DB2则会报错:
SELECT ‘abc’ FROM XXX WHERE ‘1’ in (1) 在Oracle下可通过,在DB2中会报错。
在Oracle中使用"Where 字符型字段=整型"是允许的,DB2则会报错:
SELECT ‘abc’ FROM XXX WHERE ‘1’=1 在Oracle下可通过,在DB2中会报错。
DATE数据类型
Oracle中DATE型带有时分秒,但DB2下DATE型只带有年月日且可以作为字符串直接操作,DB2中要记录时分秒必须使用时间戳型(TIMESTAMP), DB2的日期和时间戳都可以被直接用字符串指定。
Decode函数
Oracle中使用decode()函数来做判断语句:
decode(sex,0,‘男’,1.‘女’) 即为将sex域中的0换为男,1换为女。
在DB2中要实现这个功能需要用CASE WHEN写法:
CASE sex WHEN 0 THEN ‘男’ WHEN 1 THEN ‘女’ ELSE ‘其他’ END
NVL函数
在Oracle中NVL函数主要用来处理空值,即将域中空值替换为指定值:
SELECT NVL(F_AREAID,‘空’) FROM MASA_USER
在DB2中需要使用兼容性写法COALESCE
SELECT COALESCE(F_AREAID,‘空’,F_AREAID) FROM MASA_USER
获取系统当前日期
在Oracle中使用SYSDATE,而在DB2中使用CURRENT DATE
获取特定数量的数据
在Oracle中使用ROWNUM:
SELECT * FROM TABLE WHERE ROWNUM <= 10
在DB2中使用FETCH:
SELECT * FROM TABLE FETCH FIRST 10 ROWS ONLY
最后
这一篇写了很久,主要是确实对数据库的理解不深,需要看的资料比较多,最后主要学到的对我来说有用的东西可能还是操作层面的SQL语法,如果以后的工作中还发现新的区别再来这里补充。





