序言
最近有些好奇微信PC版的聊天文件在本地是如何保存的,因为这些文件要兼顾可以快速随时访问,又要不能直接在文件夹中展示,所以稍微研究了一下,发现原来这些文件虽然是被加密过,但解码的方法其实非常简单(与其说被加密不如说只是让它不能直接打开而已),这里就分享一下这个dat文件的解码原理和我写的解码小脚本。
正文
方法论
我首先找到的是这篇文章 ,通过这篇文章我知道了两个原先不知道的小知识,第一是jpg有固定的标识符FF D8来标记图像的起始位置,第二是dat文件的加密方式是对图片文件的每一个字节做一个固定数值的异或运算(XOR)(既以比特(bit)各位计算,两值不同返回1,两值相同返回0,运算符号为⊕),异或运算的一个重要特性就是自反性,既:
a ⊕ b ⊕ a = b a \oplus b \oplus a = b
a ⊕ b ⊕ a = b
而我们现在已经有了一个经过特定数值x异或处理过的FF D8,那么我们只要在这个基础上再使用FF D8进行异或运算就能倒算出这个特定的数值x,既:
0 x f f d 8 ⊕ x ⊕ 0 x f f d 8 = x \mathrm{0xffd8\ \oplus}\ x\ \mathrm{\oplus \ 0xffd8}=x
0xffd8 ⊕ x ⊕ 0xffd8 = x
然后使用这个计算出来的x将dat文件中的所有字节都进行异或运算就可以得到原来的图片数据了。我们可以先小试一下实际是不是这样。
小实验
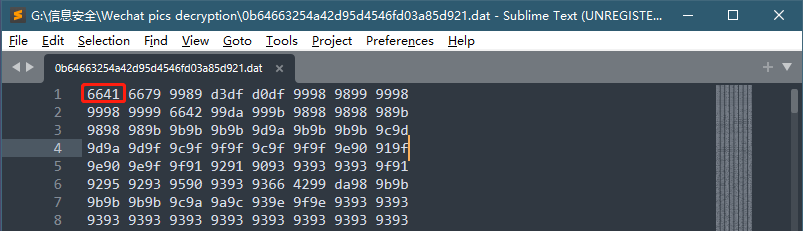
我们就借用这位大佬 的代码和思路,先随便拿张图试试。先用sublime text编辑器 的十六进制模式查看一下这个被抽中的幸运图片的内容:
这时用计算器的程序员模式算一下0 x 6641 ⊕ 0 x f f d 8 \mathrm{0x6641\oplus 0xffd8} 0x6641 ⊕ 0xffd8
那就把这个幸运图片(.dat)的每一个字节对99做一次异或运算吧:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def imageDecode (f ): dat_read = open (f,"rb" ) out = "00.png" png_write = open (out, "wb" ) for now in dat_read: for nowByte in now: newByte = nowByte ^ 0x99 png_write.write(bytes ([newByte])) dat_read.close() png_write.close() name = "0b64663254a42d95d4546fd03a85d921.dat" imageDecode(name)
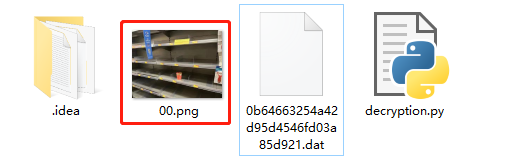
运行后发现果不其然,图片信息被还原了:
看来方法是没有问题的,但似乎用计算器算x这个步骤有些脱裤放屁的嫌疑了,直接用Python算好了自己代进去不就好了,这样就可以把解码步骤一般化啦。那就改进一下吧。
改进一下
我想让解码的工作更加方便快捷一些,只需要把我们的exe文件放进微信的存储文件夹下运行就可以自动解码所有的文件并且放在一个固定的文件夹中,这里我假设每个文件夹中的dat文件都用相同的字节加密,所以每次打开一个文件夹,程序都会用文件夹中的第一个dat文件的第一个字节来解码得到解码字节。
但事实上根据我的观察,似乎这个解码字节似乎是根据主机与用户号生成,也就是说同一个用户在同一台主机中的图片文件都被用同一个解码字节加密成dat文件,但用这个程序也不需要管那么多了,只要你没有把不同用户的dat文件混合在一个文件夹下就都没有问题。于此同时,我还给程序加了一些可视化的进度条,这样解码大量文件时也不会等得茫然。废话少说,放代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 import osfrom tqdm import tqdmimport shutildef get_decode_key (file ): dat_read = open (file, "rb" ) head = dat_read.read(1 ) x = int .from_bytes(head, byteorder='big' ) dat_read.close() return x ^ 0xFF def image_decode (file_in, file_out ,key ): dat_read = open (file_in,"rb" ) out = os.path.join(file_out)+".png" png_write = open (out, "wb" ) for now in dat_read: for nowByte in now: newByte = nowByte ^ key png_write.write(bytes ([newByte])) dat_read.close() png_write.close() def decode_all (): fsinfo = os.listdir() num_folders = len ([x for x in fsinfo if os.path.isdir(x) and x not in (".idea" , "result" )]) i = 0 if 'result' not in fsinfo: os.makedirs('result' ) else : shutil.rmtree('result' ) os.makedirs('result' ) for folders in fsinfo: if os.path.isdir(folders) and folders not in (".idea" , "result" ): i += 1 print ("\r" , end="" ) print ("Folders to be decoded: %s/%s" % (i, num_folders)) temp_path = os.path.join("result" , folders) os.makedirs(temp_path) key_flag = False dat_files = [x for x in os.listdir(folders) if x.endswith(".dat" )] if len (dat_files) == 0 : print ("No dat file in this folder" ) else : for files in tqdm(dat_files, desc="Folder%s: " % i): output_path = os.path.join(temp_path, files) if key_flag is False : file_path = os.path.join(folders, files) key = get_decode_key(file_path) image_decode(file_path, output_path, key) key_flag = True else : file_path = os.path.join(folders, files) image_decode(file_path, output_path, key) if i == num_folders: print ("All Jobs Done!" ) def main (): decode_all() if __name__ == '__main__' : main()
打包测试一下
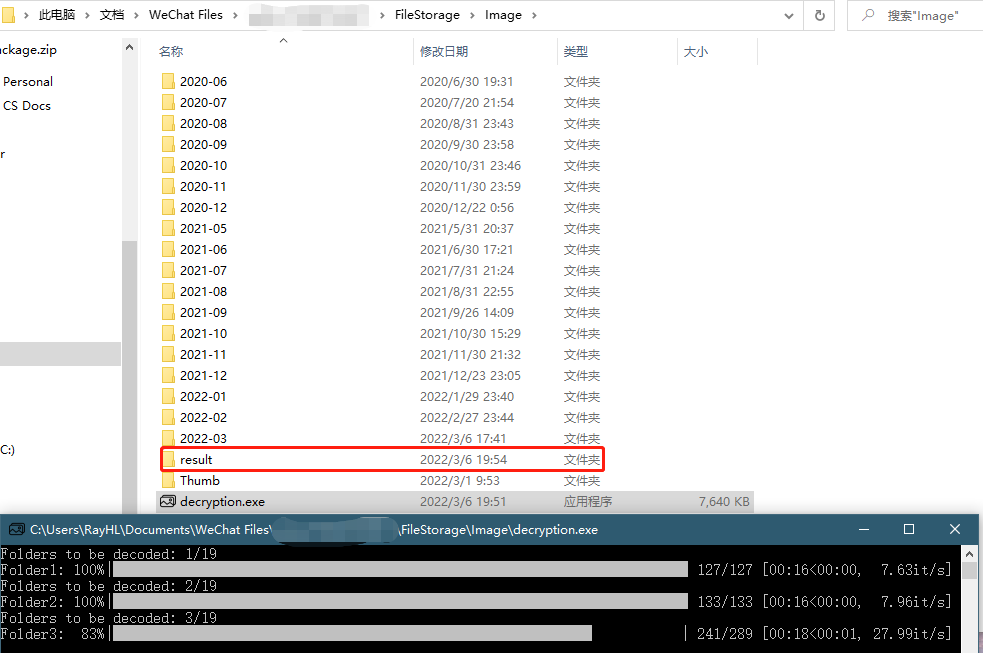
用py2exe包把文件打包成一个exe文件,大小大概7.6M比较合理。把这个exe文件复制去我自己的微信image文件夹下双击运行,程序就开始慢慢跑起来了。
结果非常完美!运行体验也很好!
软件下载
我把这个exe文件放在这里转需,也可以看看自己的微信里都缓存了些什么玩意:文件下载
补充一个小bug的解决思路
我发现有一种情况可能导致解码失败,那就是当微信聊天的图片不仅仅有jpg格式还有png格式时,我们如果第一步获取解码字节是从这些png加密的dat文件中获取,这些图片的文件头是89 50(来自这篇博文 ,非常有用马克一下),但我们是使用jpg格式的文件头FF D8来获取,这会导致获得错误的解码字节,从而导致一整个文件夹都解码失败。
我已经想到了一个解决办法,因为dat文件不管是png图片还是jpg图片都会被同一个解码字节进行异或处理,那也就是说因为异或运算的自反性,使用加密后的字节1与加密后的字节2进行异或运算所得的结果与其加密前的异或结果会是一样的,如下式:
( 字节 1 ⊕ x ) ⊕ ( 字节 2 ⊕ x ) = ( 字节 1 ⊕ 字节 2 ) ⊕ x ⊕ x = 字节 1 ⊕ 字节 2 (\mathrm{字节1\ \oplus}\ x)\ \mathrm{\oplus \ (字节2\ \oplus}\ x)=(\mathrm{字节1\ \oplus\ 字节2})\ \mathrm{\oplus \ }x\ \mathrm{\oplus \ }x=\mathrm{字节1\ \oplus\ 字节2}
( 字节 1 ⊕ x ) ⊕ ( 字节 2 ⊕ x ) = ( 字节 1 ⊕ 字节 2 ) ⊕ x ⊕ x = 字节 1 ⊕ 字节 2
而png的文件头89 50进行异或运算结果为D9,这与FF D8两字节的异或运算结果27是不一样的,由此我们可以增加一个判断,将dat文件的头两个字节进行异或运算,若得出结果为27,则判断加密前为jpg文件,使用FF D8来获得解码字节;若得出结果为D9,则判断加密前为png文件,使用89 50来获得解码字节。只要解码字节获取成功,后面的解码操作其实都是一样的。但我懒得改代码了,反正也没那么多png图片,有需要的自己把思路拿去改吧。
最后
通过这一次的这个好奇心驱使下的学习,实际上除了主题相关的图片格式,微信dat文件加密方式等等以外,最重要的是我重新复习了一下Python操作文件,显示进度条以及打包等等内容,都是非常基础但需要熟能生巧的技能。
[第8篇]