[编程算法] 公司项目需要的自动化测试Selenium文档解读
序言
基于刚进公司时接手的一个自然语言处理+自动化测试的项目,这篇文章我会主要覆盖Python的Selenium包的文档解读,由于在HKU时的毕业项目便涉及各种在线论坛的评论爬取,我对Selenium并不算陌生,但由于Selenium的内容功能是比较多的,本篇除了一些基础知识以外,我会重点关注与公司项目有关的部分。
正文
背景介绍
刚进公司的时候接手了一个前人的自然语言处理+自动测试项目。因为现在公司有一个由集团设定报价逻辑的报价系统,通常来说由代理或核保人员输入客户的相关资料便可以完成报价,但这个系统报价汽车险时要输入的资料非常繁琐,导致代理不愿意使用这个系统报价,影响报价率。考虑到这个系统中很多资料是没有意义的,因此前人建议代理直接填写车型排量司机年龄等必要资料,并用Python做了一个自动报价工具。
这个工具由两个大部分组成,第一个部分是自然语言处理,即使用Cosine Similarity算法将代理输入的车型信息与公司系统中的车型信息匹配,有机会我会再写一篇文章讲讲这部分。第二部分则是自动化测试,使用匹配到的车型信息利用Selenium自动填写资料并返回报价。前人对第一个部分的完成度是比较高的,因此我只是对代码规范性和循环逻辑稍作调整便可以获得较好的文本匹配和稳定性。但第二个部分他的测试显然是不够的(毕竟是未完成的项目),网站中有非常多的特殊情况例如某些资料未填写时其他资料将不会显示,司机年龄和驾龄都很小时会直接弹出错误信息不予报价,有时网站弹窗提示时需要先将该弹窗关闭才能继续操作等等。
但由于代码本身涉及公司内部报价网站的架构,我不会在这里分享具体的代码或逻辑,因此本篇我会分享一些我在解决这些问题时通过Selenium with Python学习到的知识。
Selenium文档解读
在开始之前,我想先通过这个问题下大佬们的回答介绍一下Selenium和Webdriver是什么。Selenium是一个适用于各种浏览器和平台的网页应用的自动测试套装,各个主要的浏览器提供商都已将Selenium作为其浏览器内部部分进行支持,而我使用的则是Selenium为Python接入提供的一个包。而Webdriver则顾名思义是一个连接你的脚本和浏览器的一个程序,其通过在浏览器中注入Javascript的方式来控制浏览器行为,你可以想象你通过你的Python脚本告诉这个“司机”(driver)如何开这个"车"(browser)。
基本约定
在介绍具体的函数之前,首先介绍一下Selenium API的一个基本约定。Selenium API 有一些属性(Attribute)是可调用的(即方式methods),有一些属性是不可调用的(即特性properties),所有可调用的属性都以圆括号结尾。如下例:
1 | driver.current_url #这是一个property,是一个值。具体来说是"现在这个页面的URL"。 |
打开网页
举例来说,当使用webdriver.Chrome()将Chrome driver设定为实例(instance)并将该实例赋值给driver时,使用driver.get(“xx网址URL”),浏览器便会被打开并导航至该指定网址,需要注意的是Webdriver会等到网页完全加载完毕之后才将控制权返回你的脚本,也就是说在这个阶段你通常不用担心你的程序会急着在没有加载出来的网页中操作或找寻你要的东西,但如果网页使用了大量的AJAX(Asynchronous JavaScript And XML, 用于直接在已加载的网页中读取网络服务器数据),那么driver可能无法判断网页是否完全加载,如果要确保网页完全加载可能需要使用selenium的waits函数。
定位元素
当我们进入了想要测试的网页之后,首先要解决的问题就是如何让driver找到你想要互动的元素,Selenium提供的方式非常丰富,包括id, name, Xpath, link text, partial link text, tag name, class name甚至css selector。
举例说明
举例来说,如果我们有一个如下的网页:
1 | <html> |
那么你可以分别通过下面这些方式定位你想要的各个元素:
1 | login_form = driver.find_element_by_id('loginForm') # 通过id定位到表格 |
上面这些find_element_by_*的方式都只能用于找到页面中第一个出现的符合条件的元素,而如果把方式换成相应的find_elements_by_*那么它将以list的形式返回页面中符合条件的所有元素(但注意没有 find_elements_by_id, 因为一个html文件中id只能是唯一的)。
另外除了以上这些public methods以外,Selenium还提供了两个private methods:
1 | from selenium.webdriver.common.by import By |
需要注意的是,这两种方式并没有本质区别,因为find_element_by_*就是以find_element定义的,参考这里:
1 | def find_element_by_xpath(self, xpath): |
更多关于XPath
XPath通常来说是用得最多的定位元素的方式。XPath本身是一个专门用来定位XML文件中节点(nodes)的语言,由于HTML也可以由XML实现(XHTML), 这也使得Selenium用户可以用这个强大的语言来定位网页元素。XPath之所以用得比较多是因为理论上它可以定位到网页中的任何一个元素,无论它有没有被用id或name定义过。
XPath在selenium中使用也可以有两种方式,绝对引用或相对引用:
绝对引用(不推荐):绝对引用的路径是从root(html)层开始往后推,虽然绝对引用可能可以更精确定位到想要引用的元素,但它的缺点却在于网页文件的一点点变动都会导致引用不正确。相对引用:相对引用是定位目标元素到它附近的(最好是母元素)有id或name属性的元素的相对路径,虽然有几率错过真正想找的元素(比如有两个name相同的元素),但引用相对页面变动也更加稳定。
举例来说,在上面这个[网页][#举例说明]中,我们可以使用很多不同的XPath来定位同一个元素:
1 | login_form = driver.find_element_by_xpath("/html/body/form[1]") # 绝对引用定位form |
W3School有更细致更全面的XPath有关的教程。
等待加载(Waits)
自动测试项目中非常影响实际测试效果的一个因素就是这个部分了。Waits顾名思义就是让程序等待,Python的time包中有一个sleep()函数就可以做到这点,让程序暂停执行一段设定的时间。那么Selenium中的·有什么不同呢?time.sleep()是没有任何其他条件地让程序暂停一段时间,但Selenium中的waits却是令程序在某个条件被达成之前等一段设定的时间。换言之一旦条件达成便立即执行。Selenium有两种waits。
显式等待(Explicit waits)
使用显示等待会让程序在给定条件出现以前等待一段时间,超过这段时间或达成条件才进行下一步操作。默认设定下,程序会每隔500毫秒判断一次条件是否达成。以这段代码为例:
1 | from selenium import webdriver |
expected_condition是selenium预设的一些判断条件的函数,代码中的EC.presence_of_element_located()接受locator参数,而locator则是一个(by, path)的元组(Tuple),这也是这里有两层括号的原因。当这个元素可以被定位后该函数会返回一个true(Boolean), 如果无法被定位这个函数则会返回not null。(参考这里)
expected_condition提供的预设好的网页条件还有以下这些:
- title_is
- title_contains
- presence_of_element_located
- visibility_of_element_located
- visibility_of
- presence_of_all_elements_located
- text_to_be_present_in_element
- text_to_be_present_in_element_value
- frame_to_be_available_and_switch_to_it
- invisibility_of_element_located
- element_to_be_clickable
- staleness_of
- element_to_be_selected
- element_located_to_be_selected
- element_selection_state_to_be
- element_located_selection_state_to_be
- alert_is_present
如果这些预设好的条件无法满足你的需求,你还可以自己定义等待条件,参考文档中的方法。
一些容易有疑问的条件
上面这些预设的等待条件中有几个非常相似的条件,我特别拎出来讲一讲他们的区别:
- presence_of_element_located:只要元素在文件物件模型(DOM)
出现便会返回true。 - visibility_of_element_located:元素在DOM中
出现并且高度和宽度大于0 (visible)才会返回true。 - element_to_be_clickable:元素需要
出现,可见并且可以互动才会返回true。
显然越下面的条件比上面越加严苛,如果你想让你的脚本按一个button,那么比起它的出现或者可见,你更应该关心它是不是已经可以被按了。其他的条件的具体解释也都可以参考源代码中的写法和注释。
隐式等待(Implicit waits)
隐式等待比显式等待在写代码的层面上更加简单,针对性也没有那么强。它只是让driver不能立马在DOM中定位到某项元素时,多等一段设定好的时间。隐式等待时间的默认设置为0,在一次Webdriver的使用中它只需要被设定一次。使用方式如下:
1 | from selenium import webdriver |
操作元素
Selenium中可以用来操作元素的方式实在是太丰富了,我在这篇中只会提到我项目中会使用到的,也是最简单最基础的几个操作方法。
点击元素
非常直观,在你找到的元素后面调用.click()方式,便可以让driver尝试点击这个元素。
填写输入
当你定位到一个可以input的元素之后,可以使用send_keys("whatevertext")来将引号中的内容填入Input元素中。需要注意的一点是,send_keys()也可以发送其他如回车(Keys.ENTER),空格(Keys.SPACE)等键盘上的功能键的指令 ,因此这个函数可以在任何元素上被调用。另外在文本框中文字不会将已有的文字清除,如果文本框中已经有文字,send_keys()只会在已有文字的后面附上新加的文字。因此通常使用此函数在文本框中输入文字时建议先使用.clear()将文字清除。
选择表单
Selenium使用户可以获取下拉表单的选项数据,并且使用setSelected来选中特定OPTION标签的元素。可用的选中方式如下:
1 | from selenium.webdriver.support.ui import Select |
其中select_by_visible_text("text")和select_by_value(value)的区别在于,想要选中给定的<option value="foo">Bar</option>这个选项,需要使用select_by_visible_text("Bar")或者select_by_value("foo")。
另外,Select类中还有一些非常有用的公式如:
all_selected_option: 用于返回一个select标签下的所有已选项的list。deselect_all(): 清除所有已选项(仅对支持多选的元素有效)。options: 返回表单中所有可选项。
获取文字
要从网页中爬取文字就一定要用到元素的text属性,该属性即可返回元素中的文字。
Chrome开发者工具
虽然现在其实我对网页和网络的运作方式还处于一团迷雾的状态,但因为要爬取网页元素,也算是小小接触了Chrome中按F12就可以打开的开发者工具,要写关于网页的脚本这个界面是一定绕不开的。下面我会介绍两个我作为萌新自己乱点摸索出来的对爬虫或自动测试非常有用的两个功能。因为是自己摸索,所以很有可能走了弯路都不自知。如果有更好的方法,或者完整的玩转F12的指南手册,还希望各位大佬在评论区不吝赐教。
在网页文件中定位元素
刚刚接触开发者工具的时候完全不知道如何在花里胡哨的html文件中找到网页中的某个元素,只知道在body里面一个一个往下找,对应着页面上的高亮一点一点往里点,后来才知道原来用Chrome的这个功能就可以快速定位到元素在html文件中的位置,非常方便。这是全世界都知道所以才没有被任何教程提及吗?
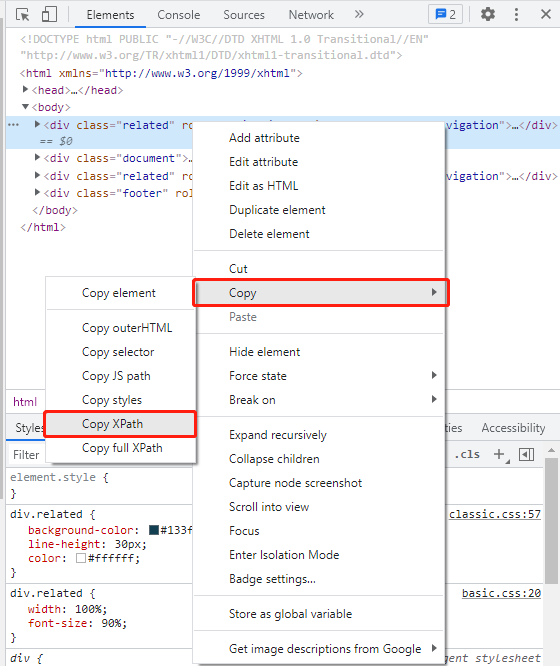
得到元素的XPath
同样也是一个大概所有人都知道(所以没有在任何教程里见到提及),但我是自己玩了老半天才偶然发现的功能。原来在开发者工具中右键点击元素,找到复制→复制XPath就可以直接得到这个元素相对路径的XPath,不确定Chrome的算法是怎样,但似乎这个复制XPath是在尽量选择不会导致ambiguity的方式引用。
最后
因为这个项目的机会,我对网页自动测试甚至是爬取网页的经验又增加了不少(当然我知道一般爬取网页的首选项肯定是BeautifulSoup,毕竟不经过浏览器互动的爬取会稳定不少,但现如今大部分的网页不用浏览器互动已经啥都爬不到了)。另外之后有时间我会再把项目前半部分关于Cosine Similarity文本相似度匹配的部分整理好再发一篇。
[第4篇]





